Originally published on Medium. Republished here as part of TapData’s real-time data architecture series.
A while ago we were working on a project that required exposing clinical data through FHIR. On paper it sounded straightforward: take data from existing hospital systems, map it to FHIR resources, and expose it through APIs.
In practice, things turned out to be more complicated. Most of the upstream systems were legacy operational databases, and rewriting them was simply not an option.
That constraint ended up driving almost every architectural decision we made.
The first instinct: just expose a FHIR API
When starting from that constraint, the first instinct is usually the same: just expose a FHIR API.
The reasoning feels straightforward. The operational systems already contain the data. If we map their schemas to FHIR resources and assemble the response at request time, we can avoid building another data layer. The API simply queries the source systems, joins the data it needs, and returns the FHIR resource.
At first glance, this seems perfectly reasonable. In fact, many early designs for interoperability platforms start exactly this way.
The problem is that this approach quietly assumes something that rarely holds in real hospital data: that the data needed for a resource is available at the same time and in the right order.
In practice, that assumption breaks very quickly.
Most FHIR resources are not built from a single system. A Patient resource might combine identifiers from a registration system, contact details from another system, and insurance information from yet another. An Encounter might later accumulate observations, diagnoses, and orders coming from different clinical subsystems.
More importantly, those events rarely arrive in a clean sequence.
Some systems only finalize records late in the workflow—for example, an encounter may only become complete when the patient is discharged. Others emit information much earlier, such as lab observations generated during the visit. Backfills and delayed inserts are also common in healthcare systems.
As a result, the data that eventually forms a single FHIR resource often arrives out of order.
That detail turns out to matter a lot.
An architecture that quietly assumes “the parent record exists when the child arrives” can work perfectly in early demos or controlled testing. But once real production traffic starts flowing, that assumption quickly collapses.
After encountering this problem in practice, most teams tend to converge on a few architectural patterns. In our case, three approaches surfaced repeatedly:
-
building a FHIR API gateway that joins source systems in real time,
-
constructing resources through a full streaming stack,
-
maintaining FHIR resources as an incremental read model.
Each of these paths looks reasonable at first. But their behavior under real healthcare workloads is very different.
The rest of this article walks through those three approaches and why they lead to very different operational outcomes.
Option A: building a FHIR API gateway
The first architecture we tried was the most direct one: build a FHIR API gateway and assemble resources in real time.
The idea was straightforward. When a downstream system requests a FHIR resource, the gateway queries the relevant upstream databases, performs the joins in memory, maps the result into the FHIR schema, and returns the assembled resource to the caller.
At first glance, this design feels almost obvious. There is no intermediate storage layer, and no additional data pipeline to maintain. Every response is constructed directly from the operational systems that own the data, so there is no synchronization delay or consistency gap introduced by replication.
From a conceptual standpoint, the architecture is also very easy to explain. The gateway acts as a translation layer between operational databases and the FHIR API surface.
For small systems, this approach can work surprisingly well. If the number of data sources is limited and the query volume is low, the gateway simply becomes another service that performs read operations and schema mapping.
The complications begin to appear once we examine how a typical FHIR resource is actually constructed.
FHIR resources rarely come from a single table or even a single system. A Patient resource might combine identifiers from a registration system, contact details from another system, and insurance information maintained elsewhere. An Encounter resource can later accumulate laboratory observations, diagnoses, medication records, and other clinical events coming from different subsystems.
Constructing a resource therefore requires joining multiple datasets that live in different operational databases.
At that point the gateway effectively becomes a distributed query engine. For every incoming request it must query several upstream systems, wait for their responses, assemble the results in memory, and then perform the transformation into the final FHIR structure.
The most immediate consequence is that response latency becomes difficult to predict.
Because each request depends on multiple upstream systems, the overall response time is determined by the slowest one involved in the query. In hospital environments this becomes particularly visible during operational peaks. If both HIS and LIS are experiencing heavy load, the FHIR API must wait for those systems to complete their queries before it can return a response.
In practice, we observed that p95 latency could easily stretch into the range of ten seconds or more under peak conditions, and timeouts were not uncommon when upstream systems were under pressure.
The root cause is simple: the architecture performs its most expensive and variable work directly on the request path.
Another issue becomes visible as the system evolves: tight coupling to upstream systems.
Because the gateway queries operational databases directly, it implicitly depends on their schemas and availability. A schema change in a source database can break the mapping logic. Maintenance windows or transient outages can propagate directly to the FHIR API layer.
Over time, the gateway starts to resemble what engineers often describe as a distributed monolith. It appears to be a separate service, but in reality it cannot function without the coordinated behavior of multiple upstream systems.
This coupling also introduces operational challenges across teams. In most hospital environments, the operational systems are owned by different groups and evolve independently. A tightly coupled gateway forces coordination that is difficult to maintain in practice.
As concurrency increases, another problem emerges: resource consumption.
Constructing complex FHIR resources requires joining and aggregating multiple datasets, often involving one-to-many relationships. Under concurrent workloads, the gateway must perform these joins repeatedly for each request.
This increases CPU and memory usage within the gateway itself, but it also places additional read pressure on the source databases. Every API request effectively translates into multiple database queries against systems that are already serving operational traffic.
In high-concurrency scenarios this creates a feedback loop. Increased API demand generates more read traffic on operational databases, which slows those systems down, which in turn increases API latency.
A more subtle limitation also appears over time: the lack of reuse.
Because the gateway constructs resources on demand, the result of each join exists only for the duration of a single request. Even when multiple downstream applications request similar data, the gateway repeats the same joins and transformations each time.
Without a persistent read model, the system continuously recomputes the same resource structures.
None of these issues are obvious at the beginning. In fact, the architecture often works well during early testing, where the data volume is small and the system behavior is relatively predictable.
The limitations only become visible once the system operates under realistic workloads: multiple heterogeneous data sources, variable data shapes, and higher levels of concurrency.
At that point it becomes clear that assembling FHIR resources directly on the request path introduces too much variability and operational coupling to remain sustainable.
This realization forced us to look for another approach.
One obvious candidate was to move the assembly work into a streaming pipeline and construct the resources continuously as data changes arrived.
Option B: a full streaming pipeline (Debezium + Kafka + Flink)
Once it became clear that assembling FHIR resources directly on the request path would not scale well, the next idea was to move the work into a streaming pipeline. Instead of joining data at query time, the system could continuously process changes as they happened.
A typical design looked something like this:
-
CDC events are captured from operational databases using Debezium.
-
The change events are written into Kafka topics.
-
A stream processing layer (usually Flink) consumes those topics, performs joins and transformations, and constructs the FHIR resources.
-
The resulting resources are written into a serving store.
From a data engineering perspective, this architecture is powerful.
Kafka provides a durable event log with high throughput, buffering, and replay capabilities. Flink offers sophisticated stream processing primitives that can handle complex event transformations, windowing, and aggregation logic.
On paper, this approach seems like a natural fit for assembling FHIR resources, which often require merging events from multiple systems.
In fact, for a while this architecture looked very promising.
But the deeper we examined the implementation details, the more we realized that the real challenge was not streaming—it was state management.
Resource construction becomes a state machine
FHIR resources are not simple event transformations.
Consider something as common as an Encounter and the observations generated during that encounter. Observations may arrive before the encounter record is finalized. Some may arrive long after the initial record is created. Others may be corrected or backfilled later.
In a streaming pipeline, handling this behavior requires maintaining state across multiple events.
For each FHIR resource type, the system must answer questions such as:
-
Has the parent record arrived yet?
-
If a child event arrives first, where should it be stored?
-
When the parent event eventually arrives, how should all pending children be merged?
-
If additional children arrive later, how should the resource be updated?
In Flink, these questions translate into keyed state management, state backend configuration, checkpointing strategies, and out-of-order event handling.
And this is not a single state machine.
Each FHIR resource type tends to require its own join logic and dependency handling. A realistic system can easily accumulate dozens of stream processing jobs, each responsible for constructing a different resource graph.
This quickly turns into a significant development effort.
In one data platform team’s experience, a traditional Kafka-based ETL pipeline ended up requiring a large number of Flink jobs just to handle the join logic for different resource types. The initial implementation alone required substantial engineering time, and ongoing maintenance remained a constant cost.
Operational gravity of the streaming stack
Beyond development complexity, the operational footprint of the architecture also grows rapidly.
A typical deployment requires several independent components:
-
a Kafka cluster
-
a Schema Registry
-
a set of Debezium connectors
-
a Flink cluster
-
and the downstream storage layer
Each component must be deployed, monitored, and maintained independently.
In practice this creates a long operational chain. Production teams must monitor stream processing jobs, handle connector failures, and manage the lifecycle of multiple distributed systems simultaneously.
One organization that adopted a similar Kafka-based pipeline reported that a five-person operations team needed to monitor multiple stream processing jobs on a daily basis just to keep the system running smoothly.
For organizations that already operate a mature streaming platform, this may be acceptable. But many hospital IT teams do not have large data engineering groups dedicated to maintaining distributed stream processing infrastructure.
Source database impact
Another practical consideration is the CDC capture strategy itself.
In environments where upstream databases are sensitive to additional load, CDC methods matter.
Some Debezium capture modes rely on API polling or query-based extraction. In certain Oracle environments, these approaches can introduce noticeable overhead on the source database—sometimes reported to reach around 8% additional load.
In contrast, log-based CDC mechanisms are often preferred because they minimize direct query pressure on operational systems.
This constraint can significantly influence which CDC approaches are acceptable in production healthcare environments.
A very long data path
Finally, the architecture introduces a long processing chain:
source database → Debezium → Kafka → Flink → target storage.
Every additional stage in this chain introduces its own potential failure modes, operational concerns, and latency contributions.
Even when each component is reliable individually, the overall system inherits the complexity of the entire pipeline.
For a team evaluating the architecture, the key question becomes whether the operational and engineering investment required to maintain such a stack is justified by the benefits it provides.
In our case, the conclusion was clear: the streaming architecture was technically capable, but the engineering and operational cost was simply too high. For many healthcare organizations, the size and skill set of the IT team makes this approach difficult to sustain.
This realization pushed us toward a different direction—one that still processes data incrementally, but avoids the operational gravity of a full streaming stack.
The result was a design based on a CQRS-style incremental read model.
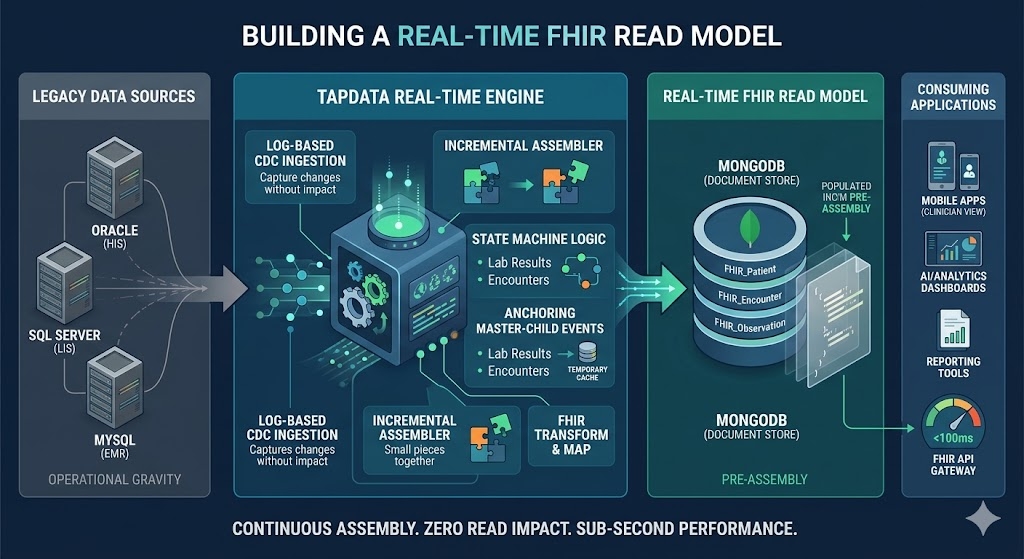
Option C: maintaining FHIR as an incremental read model
After exploring both real-time joins and a full streaming stack, we eventually reframed the problem. Instead of asking how to assemble FHIR resources during each request—or inside a large streaming topology—we started asking a different question:
What if the resources were already assembled before the query arrived?
In other words, rather than generating FHIR responses on demand, the system could maintain them continuously as a read model.
This approach follows a CQRS-style architecture. Operational systems continue to handle transactional writes, while a separate read side maintains a representation optimized for querying and interoperability.
In our case, that read side stores fully assembled FHIR resources.
The resulting architecture ended up looking roughly like this: operational databases → CDC capture → foundation data model → FHIR transformation pipeline → FHIR read model (MongoDB) → API / application access.
The implementation used TapData as the data integration layer, but the architectural idea itself is independent of any particular product.
The key is that resource assembly happens incrementally as data changes, not during queries.
Capturing changes from operational systems
The first step is capturing updates from the operational databases.
In this architecture, change data capture reads database logs directly—for example Oracle Redo Logs, MySQL Binlog, or PostgreSQL WAL—to detect inserts, updates, and deletes in real time.
Log-based CDC is particularly important in healthcare environments because upstream operational systems are often sensitive to additional load. Reading database logs allows the pipeline to capture changes without adding triggers or polling queries to the source systems.
In practice this approach introduces very little overhead on the operational databases. In many deployments the impact on TPS remains well below one percent.
For hospital IT teams, this detail is not just a performance optimization. It is often a prerequisite for deployment. Core clinical systems are rarely open to intrusive integration patterns, so a low-impact CDC mechanism becomes essential.
Establishing a foundation data model
Once captured, the change events are replicated into a foundation data layer.
This layer mirrors the schemas of the operational systems in a consolidated environment. Instead of querying production databases directly, downstream transformations operate on this mirrored dataset.
The foundation layer serves two purposes.
First, it isolates the operational systems from heavy query workloads. All joins and transformations happen downstream of the replication boundary.
Second, it provides a stable starting point for building higher-level models. The raw operational tables remain available, but the transformation pipeline can evolve independently from the source systems.
Transforming operational data into FHIR resources
The next stage is where the FHIR mapping actually happens.
In the pipeline used for this project, the transformation layer was implemented through TapData’s data processing framework (TapFlow). This layer handles the mapping logic required to construct FHIR resources from multiple source tables.
Typical transformations include:
-
field normalization and cleaning,
-
joins across related tables,
-
construction of nested document structures,
-
building references between resources,
-
and assembling arrays such as identifiers or telecom entries.
Most of the mapping logic can be expressed declaratively through a visual pipeline configuration using master–child relationships and field mappings. When more complex logic is required, the pipeline allows custom transformation nodes implemented in JavaScript.
The result of this stage is no longer raw operational data but fully structured FHIR resource documents.
Maintaining an incremental materialized view
At this point the architecture diverges fundamentally from Options A and B.
In Option A, the joins happen when a query arrives. In Option B, the joins happen inside streaming jobs.
In this design, the joins happen when the underlying data changes.
Each update to the operational systems triggers a recomputation of the affected portion of the FHIR resource. The system incrementally updates the read model so that the stored representation always reflects the latest state.
From a database perspective, this read model behaves like an incremental materialized view across multiple heterogeneous sources.
Once the view is maintained, queries become simple.
The API layer no longer needs to perform cross-system joins. It simply retrieves the already assembled resource from the read model.
This change dramatically stabilizes query performance.
Storing the FHIR read model
For the read model itself, a document-oriented database works well.
FHIR resources are inherently hierarchical and flexible. Fields such as extensions or Observation components may vary in structure, which makes rigid relational schemas inconvenient for storage.
In this architecture, each FHIR resource instance is stored as a single document in MongoDB. This allows queries to retrieve the entire resource without performing runtime joins.
The database effectively stores the result of the cross-system joins that would otherwise have been performed dynamically.
Serving data to downstream applications
Once the read model exists, multiple downstream consumers can access it.
The most obvious interface is a FHIR API server that exposes REST endpoints for clinical applications. But the same dataset can also serve other workloads.
Because the read model is stored in MongoDB, applications can access it directly through native drivers or subscribe to change streams to receive resource update events.
This makes it possible to reuse the same FHIR dataset across different types of consumers, including:
-
application backends,
-
reporting pipelines,
-
and AI or analytics workloads.
Without a persistent read model, each of these consumers would need to repeat the same integration and transformation logic independently.
Three architectural approaches at a glance
Looking at the three approaches side by side highlights the differences more clearly.
| Dimension | API Gateway + Runtime Join | Stream Processing (Debezium + Kafka + Flink) | CQRS + Incremental Read Model |
| Query latency | Depends on multiple operational systems; latency can vary widely | Typically seconds; depends on stream window configuration | Low and predictable; queries read pre-built resource documents |
| Load on source systems | High — each query reads directly from operational databases | Moderate — CDC captures changes continuously | Minimal — log-based CDC reads transaction logs |
| Development complexity | Moderate — integration logic implemented in gateway services | High — requires custom stream processing jobs and state management | Lower — transformation pipelines defined declaratively |
| Operational overhead | Small runtime footprint but operational DBs carry the query load | Multiple distributed systems to operate (Kafka, Flink, CDC connectors) | Smaller stack focused on CDC ingestion and read model storage |
| Model evolution | Changes require updates to gateway aggregation logic | Requires updating and redeploying stream jobs | Mapping changes handled in the transformation pipeline |
| Infrastructure footprint | API gateway + operational databases | Kafka cluster + stream processing cluster + CDC connectors | CDC pipeline + document store for the read model |
| Traceability and replay | Limited — resources assembled dynamically | Possible through message replay | Pipeline state and lineage tracked within the data flow |
Comparison of three architectures for exposing FHIR resources: runtime joins, stream processing pipelines, and CQRS-based incremental read models
In this project, the third approach was adopted. The remainder of this article focuses on how this architecture works internally.
Why this architecture is operationally lighter
Compared with the earlier streaming approach, this architecture significantly reduces the operational footprint.
Instead of maintaining a large streaming stack—Kafka clusters, Flink jobs, schema registries, and connector fleets—the system can be implemented as a CDC-driven pipeline that continuously maintains the read model.
The core complexity still exists, but it is contained within a smaller and more cohesive system.
More importantly, the architecture respects the constraint that shaped the project from the beginning: operational systems remain untouched and continue serving their transactional workloads.
The integration layer evolves independently.
Trade-offs
This approach is not without compromises.
Introducing a read model means adding another storage layer—in this case MongoDB—which increases storage cost and data duplication.
The read side is also eventually consistent. Updates propagate through the CDC pipeline, so the FHIR representation typically lags the source systems by seconds rather than being strictly synchronous.
For most interoperability scenarios this delay is acceptable, but it would not be suitable for workflows requiring strong transactional consistency.
There are also modeling challenges that remain open. Extremely complex FHIR resources—such as ExplanationOfBenefit—may require additional modeling effort and incremental improvements over time.
Finally, cross-resource transactional consistency is handled through versioning and eventual convergence rather than strict ACID guarantees.
Why this approach proved practical
Despite those trade-offs, this architecture provided a workable balance.
It avoided the unpredictable query latency of real-time joins and the operational gravity of a full streaming platform, while still allowing the system to maintain up-to-date FHIR resources derived from multiple operational systems.
Most importantly, it produced a solution that could actually be deployed and maintained within the constraints of a typical healthcare IT organization.
The final missing piece, however, was ensuring that the read model remained correct even when events arrived out of order.
That required a carefully designed mechanism for managing dependencies between resources.
The next section explains the technique that made this architecture reliable in practice.
Inside the pipeline: how the system actually works
Once the architectural direction became clear, the remaining work was implementing a pipeline that could continuously construct and maintain FHIR resources from multiple operational systems.
Conceptually, the system looks simple. In practice, each layer solves a different operational constraint.
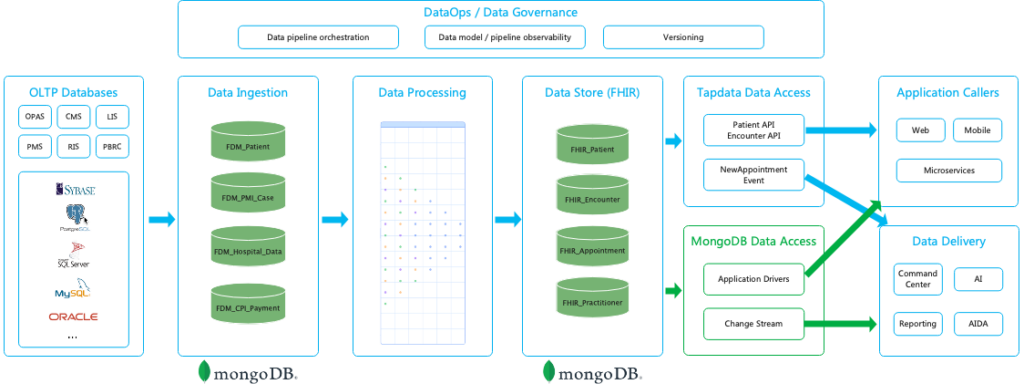
Architecture of a real-time FHIR data layer built on CDC pipelines and document-based read models
Walking through the pipeline from left to right helps explain how the pieces fit together.
Step 1: capturing change streams from multiple clinical systems
The first challenge in building a FHIR data pipeline is not the mapping logic. It is simply getting the data out of the operational systems reliably.
In a typical hospital environment, clinical data is distributed across several independent systems. Each system manages its own schema, database, and operational workload.
For example, a typical integration project may involve data coming from systems such as:
| Source system | Example tables | Related FHIR resources |
| HIS (patient index) | PATIENT_INFO, PATIENT_CONTACT, PATIENT_INSURANCE | Patient, Coverage |
| EMR (electronic medical record) | ENCOUNTER, DIAGNOSIS, ALLERGY | Encounter, Condition, AllergyIntolerance |
| LIS (laboratory system) | LAB_ORDER, LAB_RESULT, SPECIMEN | Observation, DiagnosticReport, Specimen |
| Pharmacy system | MED_ORDER, MED_DISPENSE | MedicationRequest, MedicationDispense |
Example mappings from healthcare source systems to FHIR resources
This distribution immediately creates a key requirement: the integration layer must consume changes from multiple databases simultaneously.
A single FHIR resource often depends on records stored in several systems. A Patient resource may combine demographic data from the HIS with identifiers and insurance information stored elsewhere. Laboratory Observations originate from the LIS, while clinical encounters typically come from the EMR.
Because of this fragmentation, the pipeline begins by establishing independent CDC streams for each source system.
Log-based change capture
To avoid interfering with production workloads, the pipeline relies on log-based change data capture rather than polling tables or injecting triggers into the databases.
Instead of querying operational tables directly, the CDC layer reads the database transaction logs. Depending on the system, this may involve sources such as:
-
Oracle Redo Logs
-
MySQL Binlog
-
PostgreSQL WAL
Reading database logs allows the pipeline to observe inserts, updates, and deletes with minimal overhead on the source systems.
In practice, this approach behaves more like an external observer than an additional workload on the database. For hospital IT teams—who are understandably cautious about introducing new queries against critical clinical systems—this distinction is often crucial for getting the integration approved.
Initial snapshot and incremental replication
When a new CDC pipeline is first deployed, it usually begins with a historical backfill.
The system performs an initial snapshot of the source tables to populate the downstream dataset with existing records. Once this initial synchronization is complete, the pipeline automatically switches to incremental replication mode.
From that point forward, new database changes are streamed continuously through the CDC pipeline, keeping the downstream data model synchronized with the operational systems with near-real-time latency.
For example, changes to a table such as
PATIENT_INFO may be captured from the Oracle redo log and mirrored into a downstream collection like fdm_patient_info, which serves as the foundation dataset for later transformations.Handling uneven change rates across systems
Another practical complication is that different clinical systems generate changes at very different rates.
Patient demographic records in the HIS might change relatively infrequently, but laboratory systems can generate extremely high volumes of updates. During peak reporting periods, a LIS may produce hundreds of result updates per second.
If all CDC streams were processed through a single shared pipeline, high-frequency sources could easily overwhelm lower-frequency streams and introduce unpredictable delays.
To prevent this, the pipeline treats each source system as an independent CDC task. Each task maintains its own checkpoint position in the transaction log and manages its own flow control.
This isolation ensures that a burst of activity in one system—for example a large batch of laboratory results—does not block or slow down synchronization from other sources.
From a systems perspective, the CDC layer behaves less like a single pipeline and more like a collection of coordinated change streams, each advancing at its own pace while feeding data into the downstream transformation layer.
Step 2: constructing FHIR resources from operational data
Once the change streams from the operational systems are available, the next challenge is transforming those records into FHIR resources. This step turns out to be significantly more complex than simple field mapping.
In most hospital environments, the data required to construct a single FHIR resource is scattered across multiple tables and sometimes multiple systems. A Patient resource, for example, may require demographic information, contact records, hospital identifiers, and additional attributes stored in separate tables.
In other words, the transformation layer must aggregate operational data into resource-shaped documents.
Aggregating records into resource structures
A simplified example illustrates the process.
In a typical patient master index implementation, the data needed for a Patient resource might be distributed across tables such as:
-
patient -
patient_type -
pmi_case -
hospital_data -
patient_log_info
These tables contain different aspects of the patient record, including demographic information, hospital identifiers, classification attributes, and operational metadata.
The transformation pipeline consumes the CDC streams from these tables and incrementally assembles them into a single FHIR resource document.
![]()
Example of assembling a FHIR Patient resource from multiple source tables using a transformation pipeline
The diagram above illustrates this idea: multiple relational tables feed into a transformation pipeline that produces a structured FHIR Patient document.
Instead of building this structure dynamically during queries, the system constructs it incrementally as new data arrives.
Master–child joins in the transformation pipeline
To implement this aggregation, the pipeline needs a deterministic way to join related records.
One common pattern is to treat one table as the master record and join related tables as dependent data sources.
In the Patient example, the
patient table acts as the master entity. Related tables such as patient_type, pmi_case, and hospital_data provide additional attributes that must be merged into the final resource representation.The transformation pipeline continuously processes change events from these tables. When updates occur, the pipeline recomputes the affected portions of the resource and updates the stored document.
In the implementation used for this project, this join logic was implemented using TapData’s master–child processing model inside the transformation pipeline.
Most relationships can be configured declaratively by defining the master entity, the dependent tables, and the join keys. This allows the pipeline to assemble resource structures without requiring custom stream-processing code.
Handling resource shaping and normalization
While some mappings are straightforward, many transformations require additional shaping logic.
FHIR resources contain nested structures, arrays, and references that do not correspond directly to relational schemas. For example:
-
patient names must be split into
familyandgiven -
phone numbers must be converted into
telecomarrays -
gender codes must be mapped to FHIR value sets
-
references must be constructed between resources
These transformations are typically implemented using small transformation scripts inside the pipeline.
A simplified example of a Patient resource transformation looks like this:
return {
patient_key: record.patient_key,
resource: {
resourceType: 'Patient',
identifier: [
{ system: 'adminid', value: record.adminid },
{
system: `mrn:${record.patient_hospital_data?.hospital_code}`,
value: record.patient_hospital_data?.mrn,
},
],
name: [
{
use: 'official',
family: getFamilyName(record.patient_name),
given: getGivenNames(record.patient_name),
text: record.patient_name,
},
],
gender: record.sex === 'M' ? 'male' : record.sex === 'F' ? 'female' : 'unknown',
birthDate: dobStr,
address: [
{
use: 'home',
line: addressLine ? [addressLine] : [],
city: record.ad?.city,
district: record.ad?.district,
state: record.ad?.state,
country: record.ad?.country,
text: addressText,
},
],
telecom: [
record.home_phone && {
system: 'phone',
use: 'home',
value: record.home_phone,
},
record.office_phone && {
system: 'phone',
use: 'work',
value: record.office_phone,
},
].filter(Boolean),
maritalStatus: {
coding: [
{
system: 'http://terminology.hl7.org/CodeSystem/v3-MaritalStatus',
code: record.marital_status,
},
],
},
managingOrganization: {
reference: `Organization/${record.patient_hospital_data?.hospital_code}`,
},
meta: {
lastUpdated: lastUpdatedStr,
},
extension: ccCodes.map((v) => ({
url: 'http://example.org/eu/StructureDefinition/ccCodes',
valueString: v,
})),
id: record.patient_key,
}
};This transformation illustrates an important distinction. The pipeline is not simply copying fields between schemas. It is constructing a semantic resource model that follows the structure defined by the FHIR specification.
That includes building nested arrays, generating resource identifiers, creating references, and normalizing terminology values.
Handling delayed or out-of-order attributes
Another complication arises from the fact that different attributes of a resource may arrive at different times.
For example, a patient might first be registered in the HIS system, creating the master record. Additional attributes such as contact information or insurance identifiers may appear later when other systems update their records.
If the pipeline attempted to wait for all attributes before emitting a resource, the system would stall indefinitely.
Instead, the transformation layer follows an incremental update model.
When the master record appears, the pipeline emits the initial resource representation using the fields that are currently available. As additional attributes arrive from related tables, the pipeline recomputes the resource and updates the stored document.
This approach ensures that the FHIR dataset converges toward a complete representation over time, while still making partially available data usable as soon as it appears.
From a systems perspective, the transformation pipeline behaves less like a batch ETL job and more like a continuously updating resource model.
Step 3: storing the FHIR read model
Once the transformation pipeline constructs the FHIR resources, they are stored in a dedicated read model designed for efficient downstream access.
Instead of persisting intermediate relational tables, the system stores fully assembled FHIR resource documents in a dedicated read model database.
In this architecture, each document represents one complete FHIR resource instance.
This design choice has an important consequence: downstream queries no longer need to perform cross-table joins or resource assembly logic. All of the expensive integration work has already been completed upstream in the transformation pipeline.
For example, retrieving a Patient resource simply becomes a document lookup rather than a multi-table join across operational systems.
In the implementation used for this project, the read model is stored in MongoDB.
Why a document model works well for FHIR
FHIR resources are inherently hierarchical and flexible. Many resource types contain nested arrays and optional attributes whose structure may vary significantly across records.
For instance:
-
different patients may contain different
extensionfields depending on institutional profiles -
an Observation resource may contain a variable number of
componententries -
certain attributes may appear only in specialized workflows
Representing such structures in a rigid relational schema often requires large numbers of join tables or sparse columns.
A document database handles these variations more naturally. Each resource document can contain nested fields and arrays without requiring a predefined relational schema.
This flexibility aligns well with the evolving nature of healthcare data models.
The read model as a system of record for consumers
Another important design decision is that the FHIR read model acts as the primary data source for downstream consumers.
Instead of querying multiple operational systems directly, applications interact with the read model dataset.
This approach provides several advantages.
First, it isolates operational systems from query workloads. Clinical databases continue to serve transactional operations, while all read-heavy workloads are handled by the read model.
Second, it ensures that all downstream systems observe a consistent representation of the data. Every consumer—whether it is a FHIR API server, an analytics pipeline, or an application backend—reads from the same resource dataset.
In practice this significantly reduces integration complexity, because each downstream system no longer needs to reimplement its own data aggregation logic.
Handling schema evolution
Healthcare data models rarely remain static. FHIR profiles evolve over time, and institutions often extend resources with additional attributes.
The read model therefore needs a strategy for handling schema evolution without requiring disruptive rebuilds.
A common approach is to adopt a backward-compatible evolution strategy.
When new fields are introduced—such as additional extension attributes—the transformation pipeline begins populating those fields in new documents while existing documents simply leave them absent or null.
Because the underlying storage model is flexible, historical documents do not require immediate modification.
In cases where a full backfill is necessary, the pipeline can perform a controlled reset and replay of the data flow. After rebuilding the dataset, incremental updates resume and the system converges back to real-time synchronization.
This approach allows the FHIR read model to evolve gradually without interrupting downstream applications.
Step 4: serving the data to downstream systems
Once the read model exists, exposing the data becomes straightforward.
A FHIR API server can retrieve resources directly from the MongoDB collections and expose them through standard REST endpoints.
At the same time, the dataset can support other consumers as well.
Applications can access the data through native MongoDB drivers, while change streams provide a natural way for downstream services to subscribe to resource updates as events.
This means the same FHIR read model can simultaneously support clinical FHIR APIs, operational services, analytics workloads, and even AI or machine learning pipelines.
Without the read model, each of these systems would have to implement its own version of the integration and transformation logic.
Why this layered pipeline works well in practice
From an engineering perspective, this pipeline addresses several practical constraints simultaneously.
Log-based CDC ensures that the integration layer can observe changes in operational systems without introducing additional workload.
The transformation pipeline allows heterogeneous source schemas to be shaped into a consistent FHIR model.
And the read model converts complex cross-system joins into precomputed documents that can be queried efficiently.
The result is a system that maintains up-to-date FHIR resources while keeping the operational databases isolated from query workloads and integration complexity.
Handling Out-of-Order Events in Resource Construction
The pipeline described above assumes that related records arrive in a predictable order: first the master entity, then the dependent records.
In practice, that assumption rarely holds.
Healthcare systems generate events from many independent applications, and those events are delivered through CDC streams that are only loosely synchronized. As a result, records that logically depend on each other may arrive in the pipeline in unexpected sequences.
This creates a fundamental challenge for resource construction.
Many FHIR resources follow a master–child relationship pattern. A Patient resource may aggregate multiple addresses or contact entries, while an Encounter resource typically serves as the parent for clinical observations, diagnoses, medications, and other related data.
However, in real systems these events do not necessarily arrive in that order.
For example, laboratory observations may appear in the pipeline before the Encounter record that they reference. Some hospital systems only write the Encounter record after a visit has been completed, while laboratory results are generated continuously during the visit. In other cases, delayed synchronization or batch updates can cause child records to enter the CDC stream earlier than their parent record.
If the transformation pipeline attempted to join these records immediately, it would frequently encounter situations where the required parent record does not yet exist.
The system therefore needs a strategy that allows resource construction to proceed even when events arrive out of order.
Using the master record as an anchor
The approach used in this pipeline treats the master record as an anchor for resource construction.
For resources such as Encounter, the encounter record itself serves as the anchor entity. Related data such as observations, diagnoses, or medication requests are considered dependent records.
The transformation layer handles these relationships using a master–child merge strategy.
When a child record arrives but the corresponding master record has not yet appeared, the system does not attempt to construct the final resource immediately. Instead, the record is temporarily stored in a child-record cache keyed by the resource identifier—for example the
encounter_id.At this stage, the pipeline simply records that dependent data has arrived but cannot yet be attached to a resource.
No FHIR document is emitted yet, because the anchor entity is still missing.
When the master record arrives
Once the master record appears in the CDC stream, the pipeline can construct the initial resource representation.
Using the Encounter example, the transformation node receives the Encounter event and treats it as the primary record. At that moment the system queries the child cache for any previously stored dependent records associated with the same
encounter_id.These cached records may include observations, diagnoses, medication orders, or other clinical events.
All of these records are then merged with the Encounter data to construct a complete resource representation. The pipeline produces the corresponding FHIR documents and writes them to the read model store.
After the merge is completed, the cached child records are cleared because they have already been incorporated into the resource state.
This step effectively synchronizes the resource with all events that arrived before the master record.
Incremental updates after the anchor exists
Once the master record has been established, the processing model becomes simpler.
If additional child records arrive later—for example new laboratory observations—the pipeline can immediately merge them with the existing resource representation.
Because the Encounter document already exists in the read model, the transformation layer simply performs an incremental update.
The new observation is converted into a FHIR resource, and the Encounter view is updated to reflect the additional data. No caching is required at this stage because the anchor entity is already present.
In other words, the cache is only needed during the short window in which dependent records appear before their parent.
Eventual convergence of the read model
This strategy ensures that the system behaves correctly even when events arrive in arbitrary order.
The pipeline does not require strict ordering of events. Instead, it maintains enough intermediate state to guarantee that the resource representation eventually converges to the correct state once all relevant records have appeared.
From the perspective of the read model, each update incrementally improves the completeness of the resource.
This behavior aligns well with the overall architecture described earlier. Because FHIR resources are stored as incremental materialized views, the system can continuously update them as new information becomes available.
The result is a pipeline that remains robust under real-world data conditions, where delays, asynchronous updates, and partial ordering are unavoidable.
What changes when FHIR becomes a read model
With ordering handled inside the pipeline, the architecture begins to behave very differently from the earlier approaches.
In the gateway-join model, every request triggers a distributed query across multiple operational systems. The complexity of integration lives directly on the request path, which means every slow query, lock contention, or schema change can surface immediately as an API failure.
In the pipeline model, that complexity moves somewhere else.
Instead of assembling resources during queries, the system constructs them continuously as data changes. The read model gradually accumulates the results of those transformations until each document represents a fully assembled resource.
From the perspective of the API layer, this difference is profound.
A request that previously required several cross-system joins now becomes a simple document lookup. The API server no longer needs to understand how to combine records from different databases; it simply retrieves the resource representation that already exists in the read model.
This shift dramatically reduces variability in response times. Because the expensive work happens upstream in the pipeline, the query layer performs only predictable operations such as document reads or filtered searches.
Another change is the relationship between downstream systems and the operational databases.
In the earlier designs, every consumer needed to reconstruct the same integration logic. An analytics job might re-implement the joins needed to combine patient data with encounter records, while an application backend might maintain its own aggregation layer to support API requests.
Once a shared read model exists, those duplications disappear. The integration logic lives in a single pipeline, and every downstream system interacts with the same dataset.
Clinical applications can access the resources through FHIR APIs. Operational services can query the same collections through native database drivers. Analytics pipelines can read the dataset directly without re-implementing cross-system joins.
In effect, the read model becomes a stable interoperability layer between transactional systems and the rest of the data ecosystem.
Finally, the architecture also changes how schema evolution is handled.
In a runtime-join model, a schema change in one upstream system often forces immediate changes in API logic. In the pipeline model, transformations absorb those changes first. The read model evolves gradually as new attributes appear in the data stream.
Existing resource documents remain valid, while new events populate additional fields over time. When necessary, the pipeline can rebuild the dataset through a controlled replay of historical events, restoring the read model without interrupting downstream consumers.
None of this removes the inherent complexity of healthcare data integration. The pipeline still needs to deal with asynchronous systems, delayed updates, and evolving schemas.
What it changes is where that complexity lives.
Instead of appearing unpredictably during every query, it is handled inside a controlled data pipeline that continuously converges toward a stable resource representation.
And once that shift happens, exposing healthcare data through FHIR becomes far more operationally manageable.
Conclusion
Treating FHIR resources as incremental read models simplifies many aspects of healthcare data integration. Instead of assembling data during queries, the system continuously constructs resource representations as operational systems evolve.
This architectural shift moves complexity out of the request path and into a controlled data pipeline, where transformations, ordering, and schema evolution can be handled more predictably.
In practice, this makes FHIR APIs easier to operate, easier to scale, and easier to evolve as new systems are integrated.
That said, building a FHIR data layer is still an ongoing engineering effort.
Most real-world deployments begin with a subset of core resources such as Patient, Encounter, Observation, Condition, and MedicationRequest. The FHIR specification itself defines more than 150 resource types, and modeling more complex resources—such as ExplanationOfBenefit or ClinicalImpression—often requires deeper alignment with clinical workflows and domain semantics.
Another area that remains labor-intensive is schema mapping between operational databases and FHIR structures. As more systems are integrated, maintaining these mappings becomes a significant engineering task.
Recent advances in large language models suggest a promising direction here. By analyzing database schemas and sample records, LLM-based tools may help generate mapping suggestions and accelerate the configuration process for new data sources.
While these capabilities are still evolving, they hint at a future where building and maintaining a FHIR data layer becomes significantly easier.

