
In my previous piece, we explored why traditional batch processing falls short in today's fast-paced world—such as detecting fraud in finance before it's too late or maintaining real-time e-commerce stock levels. Batch jobs accumulate data and process it in batches, which can increase latency and consume excessive resources. Enter incremental computing: it zeroes in on just the deltas, dropping delays to mere milliseconds while slashing resource demands by 90% or more.
That said, stream processing often pops up as the go-to for real-time workflows. It excels at log processing and triggering real-time alerts. However, when examining your actual business requirements closely, you'll discover its limitations—especially when you need rock-solid accuracy, seamless consistency, or intricate analytics. Sometimes, it ends up complicating things more than streamlining them.
In this post, we'll pit incremental computing against stream processing head-to-head. We'll tackle the burning question: Why skip stream processing for real-time data altogether? From core concepts and pitfalls to direct comparisons and hands-on examples, this should arm you with fresh insights to nail the right tech stack for your setup.
Stream Processing: The Basics and Its Current Landscape
At its heart, stream processing treats data as an endless river—processing chunks as they flow in, ditching the wait-for-a-batch mentality. This reactive style is killer for stuff like log parsing, instant alerts, or live ETL pipelines.
Frameworks like Apache Flink or Kafka Streams pack features for aggregating over time windows, juggling state, and scaling to massive throughputs, often responding in seconds flat. Picture real-time anomaly detection in trading systems or non-stop sensor monitoring in IoT deployments, complete with immediate notifications.
Integration-wise, they offer off-the-shelf connectors for popular sources, but wrangling a messy mix of data systems usually means rolling up your sleeves for custom tweaks. This increases the learning curve and operational burden. Meanwhile, modern incremental computing tools emphasize user-friendly SQL and ready-made connectors—as we'll explore in detail.
Where Stream Processing Hits Roadblocks in the Real World
Stream processing nails it for log-heavy or monitoring tasks, but scaling it to mission-critical enterprise apps uncovers some serious friction:
-
Ops Heavy Lifting: Dealing with state snapshots, failover, and jumbled event orders eats resources and demands constant babysitting, inflating costs and skill requirements far beyond simpler batch setups.
-
Consistency Headaches: Teams want near-instant results that are dead-on accurate, but stream processing's "eventual" consistency can glitch at window cutoffs. IEEE research flags data mismatches as a major hurdle, which is a non-starter in regulated fields like banking.
-
State Management Woes: Multi-stream joins require syncing windows, a nightmare that balloons memory use (we're talking terabytes in high-volume scenarios). Backfilling? Often means replaying the whole stream, which is clunky and error-prone.
-
Narrow Sweet Spot: It's shaky for precision-dependent jobs with persistent state, like stock tracking or audit-ready reports, where dropped events throw everything off. For infrequent updates or deep historical dives, its ephemeral vibe just doesn't cut it efficiently.
These aren't edge cases—they're everyday realities that turn a shiny tech into a resource sink, demanding more team bandwidth than budgeted.
Sure, you can engineer around these, but it often confines stream processing to no-fuss, history-agnostic apps like basic alerts or aggregations. For demanding, easy-to-maintain analytics? Look elsewhere.
Head-to-Head: Incremental Computing Takes on Stream Processing
Incremental computing flips the script by honing in on changes alone. Using Change Data Capture (CDC), it snags inserts, updates, or deletes from sources in real time and surgically refreshes only what's affected.
This precision-focused approach contrasts with stream processing's event frenzy: it keeps outputs ultra-fresh and traceable, making it ideal for live views or aggregations. Today's platforms even bake in "data-as-API" features, turning raw inputs into polished services—a boon for enterprise-grade analytics.
To lay it out clearly, here's a comparison table pulled from docs and real-world runs:
| Category | Stream Processing | Incremental Computing |
| Philosophy | Event-reactive, laser-focused on minimal lag | Delta-driven, updating just the ripples |
| Prime Use Cases | Metrics dashboards, notifications, ETL on the go, lightweight sums | Core data syncing (e.g., orders/inventory), consistent reporting, fraud-proof views |
| Development Style | Windowed streams with state; wrangle disorder via watermarks—SQL add-ons feel bolted-on | Relational tables/views; pure SQL simplicity, skip the window drama |
| Data Guarantees | Eventual across flows; prone to timing quirks or edge mismatches | Bulletproof via CDC for exact change tracking |
| Handling State | In-memory or disk-backed (like RocksDB); scales but guzzles for big scopes | Durable materialized outputs; easy reuse and recovery |
| Fixing Gaps | Full-stream reruns or kludges; resource-intensive | Pinpoint change replays; efficient and scoped |
| Efficiency | Throughput champ but picky on resources; hot spots inflate CPU/memory | Change-only magic saves big; handles peaks gracefully |
| Maintenance | Tune checkpoints, parallelism, bloat control | Database-esque: watch lags, tune indexes, manage views |
| Output Access | Pipe to stores for querying/serving | Built-in queryability; seamless API exposure |
| Go-To Tech | Flink, Kafka Streams, Spark Streaming | TapData, Debezium with views, Materialize |
Bottom line: Stream processing owns high-velocity event handling and CEP in areas like oversight, alerts, or sensor streams. Incremental computing shines in seamless integration, unwavering reliability, and quicker builds—perfect for data pipelines, BI in motion, and service layers.
For a tangible feel, let's simulate a common business flow.
Real-World Showdown: Aggregating E-Commerce Orders Live
Say you're blending user profiles with order details into a single view for dashboards, streaming exports, or APIs—all updating seamlessly with high-query performance.
The Stream Processing Path
Integration Challenges: Modern enterprises manage diverse database systems (MySQL, MongoDB, ClickHouse, DB2), but stream processing tools' connectors have inconsistent support, requiring custom development and maintenance that consumes significant development time.
Here's a simplified Flink example (MySQL-focused; multi-database environments require additional integration code). This example illustrates a basic join for merging users and orders, but it also surfaces key challenges when scaled: for instance, the watermark definitions handle out-of-order events but require careful tuning to avoid accuracy issues, and the join operation can lead to memory spikes in high-volume scenarios.
-- Users stream
CREATE TABLE users (
user_id BIGINT,
user_name STRING,
user_level STRING,
country STRING,
city STRING,
signup_time TIMESTAMP(3),
WATERMARK FOR signup_time AS signup_time - INTERVAL '10' SECOND
) WITH (
'connector' = 'kafka',
'topic' = 'users',
'properties.bootstrap.servers' = 'localhost:9092',
'format' = 'json'
);
-- Orders stream
CREATE TABLE orders (
order_id BIGINT,
user_id BIGINT,
order_status STRING,
order_amount DECIMAL(10,2),
payment_method STRING,
order_time TIMESTAMP(3),
WATERMARK FOR order_time AS order_time - INTERVAL '10' SECOND
) WITH (
'connector' = 'kafka',
'topic' = 'orders',
'properties.bootstrap.servers' = 'localhost:9092',
'format' = 'json'
);
-- Merged view via JOIN
CREATE VIEW unified_view AS
SELECT
o.order_id,
o.user_id,
u.user_name,
u.user_level,
u.country,
u.city,
u.signup_time,
o.order_status,
o.order_amount,
o.payment_method,
o.order_time
FROM orders o
LEFT JOIN users FOR SYSTEM_TIME AS OF o.order_time AS u
ON o.user_id = u.user_id;
-- Export downstream (Kafka/DB) or aggregate
INSERT INTO output_kafka
SELECT * FROM unified_view;
-- For corrections or backfills (e.g., fixing a missed event), this might require expensive full stream replays, as partial updates aren't natively supported without custom logic.
This is for illustration only—actual production use may need extensive tuning for your specific setup.
Challenges: This example demonstrates foundational setup but underscores the roadblocks when applied to real-world scenarios. Beyond connector overhead (e.g., extending this to non-Kafka sources like MongoDB would need custom code), expect window size trade-offs (accuracy vs. speed) as seen in the watermark intervals—too short, and you miss events; too long, and latency spikes. Watermark adjustments for out-of-order events are evident in the table definitions, but in peak e-commerce loads, they demand constant monitoring to prevent data mismatches.
Expensive full stream replays for corrections become apparent in the export step, where fixing errors often means reprocessing everything rather than deltas. Throughput bottlenecks during peak loads and memory spikes from complex joins (like the temporal join here) can escalate quickly in multi-stream environments, turning a simple script into an ops-heavy beast. For more on Flink, check their docs.
The Incremental Computing Route
Tools like Materialize.io allow you to declare materialized views in SQL, with automatic incremental updates handled internally. Platforms like TapData provide visual interfaces: drag-and-drop joins across sources, detect changes, and output results (e.g., to MongoDB)—all with efficient memory usage.
Visualize linking users and orders into a denormalized table, piped to storage:
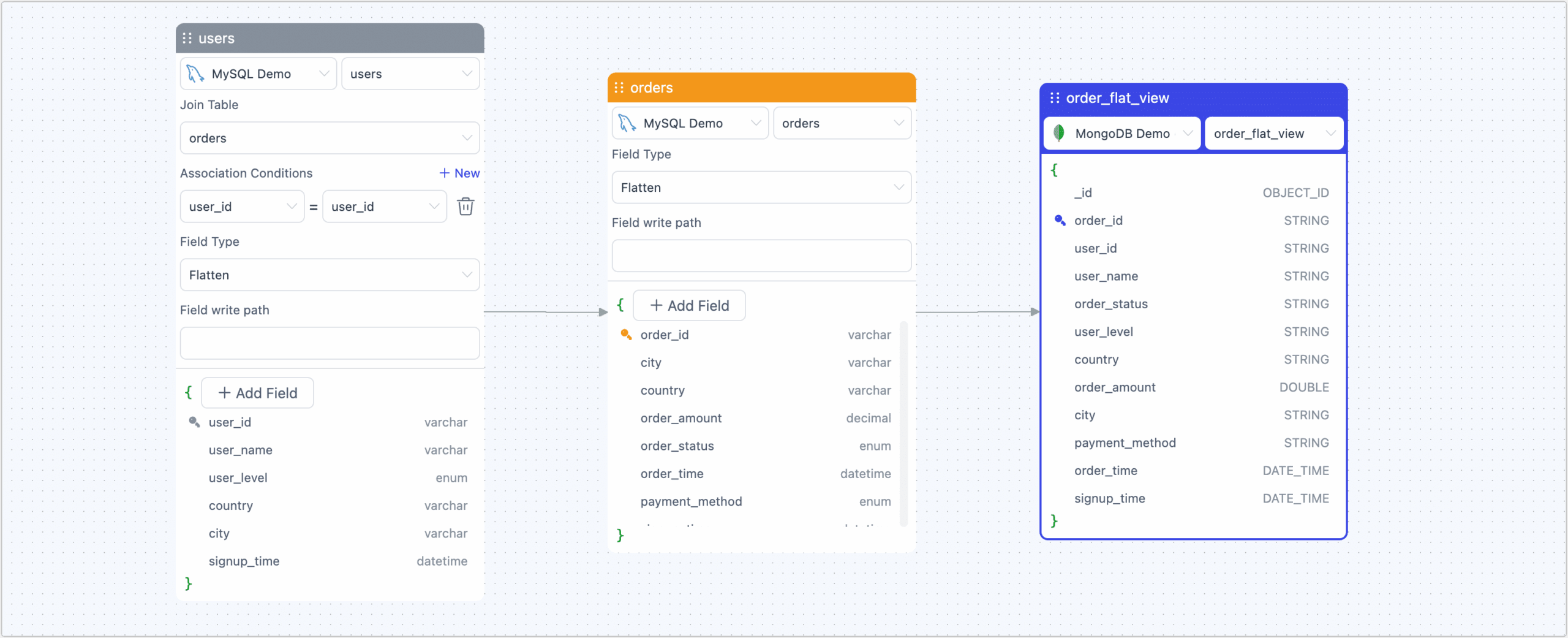
Post-launch, metrics like RPS and lag pop up in dashboards for at-a-glance health checks.
These views double as APIs for instant querying, and outputs chain into further processing—closing the loop from ingestion to deployment.
Incremental Computing's Edge in Action
This comparison highlights why incremental computing often prevails: Native support for dozens of data sources significantly reduces setup time, compared to stream processing's custom integrations.
-
Lower Learning Curve: Work with familiar tables and SQL—no complex timing concepts required.
-
Strong Consistency: CDC captures every change accurately, avoiding stream processing artifacts.
-
Efficient Resource Usage: Delta-only processing reduces overhead; durable views outperform volatile states.
-
Computational Reuse: Share computations across multiple queries for enhanced efficiency.
Final Thoughts
Both approaches shine in their own domains: stream processing for handling high-speed raw events and real-time monitoring; incremental computing for delivering refined, enterprise-grade reliability and polish.
As real-time needs surge, paths split: streams for niche events, incremental for broad analytics value. For typical teams, platforms like TapData deliver a no-nonsense upgrade with robust CDC, wide connector support, and easy API exposure—paving a sustainable real-time road.
No silver bullets in tech—align with your ops and crew. Weighing real-time options? Share your scenario below for tailored takes!

