
I’ve just wrapped up a real-time data platform project that’s been running smoothly in production for a few months now. While it’s all still fresh, I figured it’s a good time to look back on our selection process, the migration, the pitfalls we hit, and some takeaways—hopefully useful for anyone tackling real-time synchronization across heterogeneous databases.
Project Background
Our company has grown quickly over the past few years, with multiple rounds of IT upgrades, system migrations, and acquisitions along the way. This left us with a mixed bag of databases: Oracle for legacy core transaction systems, MySQL for most business applications, SQL Server for some remaining Windows-based legacy apps, PostgreSQL for newer microservices, and even MongoDB for semi-structured data. All told, we have around 50+ instances and over 3,000 regularly used tables, spread across different teams and systems—a textbook case of data silos.
The goal was to build a unified real-time analytics platform by syncing data from all these sources near-real-time into a data warehouse (we went with ClickHouse). Primary use cases included real-time dashboards, risk monitoring, and data APIs for some of the downstream applications . ClickHouse’s strengths in high-concurrency queries, compression, and OLAP performance made it perfect for delivering second-to-minute latency.
On top of that, we wanted the pipeline to be relatively low-maintenance, so data engineers could own it day-to-day and we could move toward real DataOps practices—instead of pulling in developers for every tweak.
First Attempt: Debezium + Kafka + ClickHouse Sink
As the tech leader, I usually lean toward proven open-source solutions to avoid building everything from scratch. So we naturally started with the industry’s go-to real-time CDC stack:
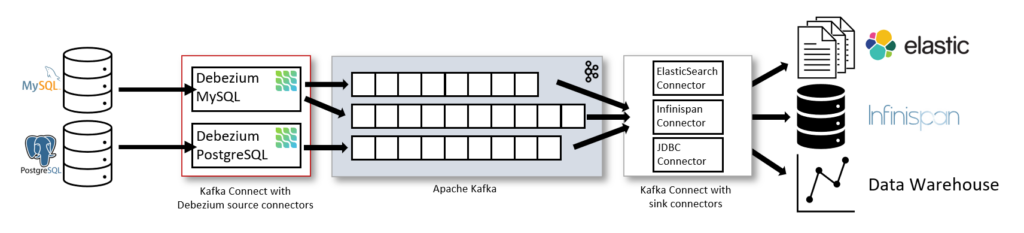
Core components:
-
CDC Capture: Debezium for change capture. Its wide range of connectors covered virtually all our source types, and the community is solid.
-
Buffering: Apache Kafka as the intermediate queue for buffering, decoupling, and scalability.
-
Landing: Kafka Connect with the ClickHouse Sink plugin to write into ClickHouse.
Although everything is open-source and “free,” we knew there were hidden costs—mainly running and managing our own Kafka cluster (Zookeeper, scaling brokers, topic lifecycle, etc.). We evaluated that upfront and felt comfortable since the team had decent Kafka experience.
We then ran a small-scale PoC(Proof of Concept) with a handful of representative tables:
-
A massive Oracle fact table (hundreds of thousands of daily changes, billions of historical rows) to test snapshot performance and resource usage.
-
Several MySQL dimension and transaction tables with nested JSON and frequent updates to validate incremental latency.
-
A high-throughput MySQL order table (~8,000 average daily QPS) to check source database overhead.
-
A wide PostgreSQL table with array and geometry types to verify type mapping.
Everything went smoothly: snapshots finished in reasonable time, incremental latency stayed at 1–3 seconds, consistency checks (row counts + MD5 on key fields) passed, and source load stayed under 5%. With an active community and plenty of references, it felt like the safe bet. We gradually expanded to all tables and rolled it out to test and production.
What Broke in Production
A few months in—as table count grew from dozens to thousands and daily change volume hit tens of millions—the problems started surfacing. Our PoC tables had fairly simple schemas and predictable change patterns, with little complex transformation or frequent schema evolution, so many real-world issues didn’t show up early.
After several retrospectives, we grouped the main pain points into three areas:
-
Transformation Complexity Debezium emits envelope JSON with before/after images. Getting that cleanly into ClickHouse usually requires Materialized Views or Single Message Transformations (SMTs). In production we constantly ran into needs like flattening nested JSON, handling cross-database type mismatches (e.g., Oracle DATE → ClickHouse DateTime), field renaming, data masking, and turning DELETEs into soft deletes. That meant either writing intricate MV SQL or custom SMTs. Schema changes—almost weekly as features rolled out—forced us to pause connectors, manually update configs, validate, restart, and sometimes backfill data. Maintenance overhead and risk of error were far higher than in the PoC.
-
Recovery and Stability Issues Interruptions are inevitable in production: Kafka cluster upgrades, connector restarts, network blips, source maintenance windows, occasional WAL lag, etc. Debezium’s at-least-once semantics often produced duplicates (ReplacedMergeTree deduplication works but struggles with array columns). During peaks, consumer lag could take hours—or half a day—to catch up. We also saw connector OOMs or task failures during large initial loads or backlog recovery, requiring manual fixes. As pipeline count grew, monitoring became a chore—we had to maintain custom alerting scripts for connector health, per-topic lag, slot sizes, etc.
-
Poor Lineage and Maintainability With multiple source types and thousands of tables, tasks were scattered across many connectors, configs spread across JSON and properties files. When DBAs or data engineers wanted to trace lineage or understand a field’s transformation path end-to-end, it was nearly impossible. Complex transformations, outlier filtering, and DELETE handling inevitably fell back on custom code or downstream SQL. This created a steep learning curve for data engineers, and our original vision of configuration-driven, low-code DataOps largely didn’t materialize—most changes still needed developers.
These aren’t fundamental flaws in Debezium + Kafka; in big-tech environments with dedicated messaging teams, the stack shines. For a mid-sized team like ours, though, the operational and people cost ended up higher than anticipated.
Second Evaluation: Moving to a Queue-less Real-Time Data Hub
Once the issues were clear, we did a full retrospective and reopened the evaluation. Options we considered:
-
Keep optimizing the current stack (e.g., add Kafka Streams for transformations or move to Confluent managed to lighten ops).
-
Switch to other open-source tools (Airbyte, Flink CDC, etc.).
-
Use warehouse-specific connectors (PeerDB for Postgres → ClickHouse, Streamkap, etc.).
-
Commercial/hosted platforms (Fivetran, Qlik Replicate, and domestic options like Tapdata).
Evaluation criteria: heterogeneous source support, low-code transformation capabilities, recovery simplicity, overall operational burden, and total cost (including headcount).
After hands-on trials and side-by-side comparison, we landed on Tapdata (community edition available). Their product architecture looks roughly like this:
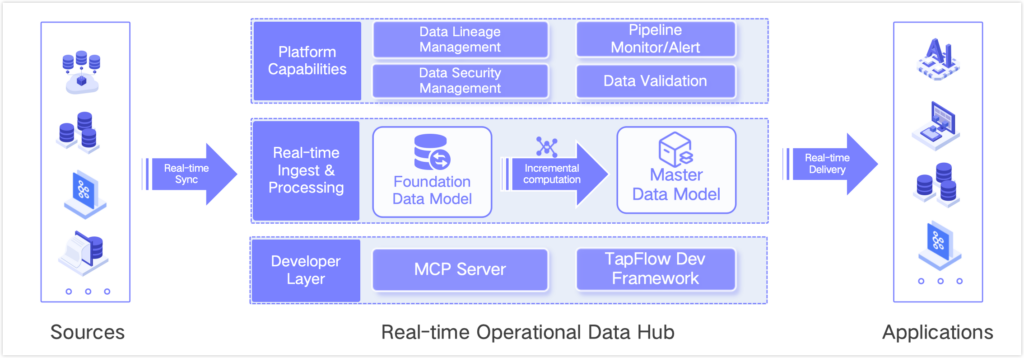
A few things that stood out for us, especially compared to the alternatives we tested:
-
Operational Data Hub (ODH) Layered Governance: Tapdata breaks the real-time data journey into clear layers—Source → Cache Layer (FDM) → Master Data Layer (MDM) → Application delivery. This fits our large-scale, multi-source setup perfectly. The FDM layer mirrors source tables in real time via CDC, so downstream processing never touches production databases again—greatly reducing load and risk. The MDM layer focuses on cleansing, standardization, and wide-table modeling to produce consistent business entities. It moved us from point-to-point syncs to true data-hub governance, making lineage tracking, impact analysis, and future extensions much easier.
-
Built-in Real-Time Processing & Delivery: Incremental computation, automatic schema evolution, drag-and-drop transformations—all without managing Kafka. Plus direct API exposure for downstream apps, which aligns well with some of our risk-control use cases that need real-time queries.
-
Team-Friendly: Low-code interface that data engineers pick up quickly, plus out-of-the-box resumption and exactly-once guarantees.
It’s been running a few months now—stable, sub-second to second-level latency, schema changes mostly handled automatically (and when manual intervention is needed, alerts notify us promptly). The data team has given positive feedback, and pipeline maintenance efficiency is noticeably higher.
A Few Personal Takeaways
First, tech selection has to match your team size and business stage. The most popular stack isn’t always the best fit. Debezium + Kafka is powerful, but it demands solid ops support. Growing teams like ours benefit more from solutions that reduce complexity and speed delivery.
Second, the real pain in real-time pipelines usually lies in governance—the “last mile” of transformation, evolution, recovery, and long-term management. A layered design like ODH structures complexity and scales better.
Finally, I used to be skeptical about low-code platforms, thinking they sacrificed flexibility. In practice, modern tools deliver strong heterogeneous support, real-time performance, and governance—and many include programmable nodes for custom logic when needed.
The pipeline is humming along nicely for now, but tech moves fast. As new requirements come (more aggregation layers, etc.), we’ll keep iterating.
If you’re working on similar real-time sync or data hub projects, feel free to share your war stories in the comments.

