There are still systems in production today that most modern data stacks barely know how to talk to.
IBM i — still widely referred to by many teams as AS/400 — is one of them. In manufacturing, finance, hospitality, and other transaction-heavy industries, these systems continue to run some of the most durable and business-critical workloads in the enterprise. They are stable, battle-tested, and deeply embedded in day-to-day operations. But that same stability often comes with a trade-off: integrating them into modern data architectures is rarely straightforward.
That tension usually stays hidden until the business asks for something the original system was never designed to provide: low-latency access to operational data for new applications. Not a nightly export. Not another reporting copy refreshed every few hours. Real-time or near-real-time data, delivered safely enough for APIs, risk controls, customer-facing workflows, and operational services.
This article looks at one such problem: how to continuously replicate data from Db2 for i on IBM i into MongoDB without putting unacceptable pressure on the source system. The challenge was not simply “moving data from A to B.” The real work was in dealing with the peculiarities of Db2 for i change capture, decoding journal data reliably, and reshaping transaction-oriented relational data into document-oriented structures that were actually useful to downstream services.
The goal here is not to present a polished vendor story or a generic “legacy modernization” narrative. It is to unpack the engineering realities behind this kind of pipeline: what makes it hard, where naive approaches fail, and what design decisions matter if you want the result to survive production.
The Practical Trigger: New Real-Time Use Cases, Old Core Systems
We ran directly into this challenge during a data integration project for a large hospitality and gaming operator in Macau. The organization had adopted electronic information systems relatively early, and several of its core transaction platforms had been running on AS/400 for many years. These systems handled the primary business transactions reliably and had proven extremely stable over time.
The source of the problem was familiar. Core transaction data lived in AS/400-based systems that had been running reliably for years. Those systems were not broken. They were doing exactly what they had been designed to do: serving transactional workloads with strong stability and tight operational controls. The problem came from the surrounding business context changing.
New requirements began to accumulate around them:
-
low-latency access to transaction data for new application services
-
customer or member profile calculations built from multiple operational systems
-
operational indicators such as points balance, redemption state, or other consumption metrics
-
API-facing services that needed current data but could not rely on the core systems directly
At first glance, this sounds like a straightforward data integration problem. In reality, it was constrained from every direction.
We could not change business logic on IBM i. We could not add highly intrusive triggers on Db2 for i tables. We could not afford a migration model that required a long downtime window. And, perhaps most importantly, we could not allow new systems to solve their latency problem by simply querying the source system directly. The core systems were optimized for transaction processing, not for becoming a shared query backend for downstream experimentation.
So the real question was not whether the data could be extracted. It was this:
How do you keep MongoDB close enough to the state of Db2 for i to serve modern applications, while treating the IBM i host as a system you are not allowed to destabilize?
That framing changes the entire design. Once source protection becomes a first-class requirement, many otherwise reasonable approaches stop being acceptable.
Why Db2 for i Is Not “Just Another CDC Source”
A lot of real-time data tooling is built on a set of assumptions inherited from mainstream databases. Teams expect some combination of accessible logs, mature connectors, transparent metadata access, and operational familiarity. Db2 for i breaks that expectation in multiple ways.
The first issue is ecosystem reality. Db2 for i is not part of the default universe for most modern data engineers. In practice, many widely used CDC frameworks and integration products either do not support it at all or support it weakly. Even when a connector exists on paper, that often says very little about production maturity. Teams used to working with MySQL binlog, PostgreSQL logical decoding, or Oracle redo logs quickly discover that IBM i is not just another relational database with a different driver. It is a different operational world.
The second issue is that the native change-capture substrate — the Journal — was not designed as a developer-friendly event stream. Journal entries are stored in IBM i–specific binary formats, rich in system metadata but not directly consumable as application-level changes. There is no clean equivalent to “subscribe to logical change events and deserialize them with a mature open-source library.” You are working much closer to the underlying storage and runtime model.
The third issue is performance sensitivity. This matters more than it might in other systems, because IBM i very often hosts the most business-critical transactional workloads in the company. A CDC design that adds tolerable overhead on an ordinary database may be unacceptable here. The technical question is always shadowed by an operational one: even if this works, do we trust it enough to put it near production?
And then there is the last-mile problem that often kills these projects before they begin: permissions and operational governance. IBM i environments are usually tightly controlled. Access to production objects, journal configuration, receivers, system values, or privileged commands tends to be wrapped in approval chains. Even a technically sound design can become irrelevant if it assumes more control over the source environment than the organization will ever grant.
That combination — weak ecosystem support, proprietary CDC internals, production sensitivity, and strict operational control — is what makes Db2 for i integration projects deceptively hard. The source system is stable, but the integration surface is not friendly.
Constraint-Driven Design: Start from What You Are Not Allowed to Do
One mistake teams often make in legacy integration work is to start from what would be convenient architecturally. In environments like IBM i, it is usually more productive to start from the opposite direction: define the moves that are off-limits, then build from there.
In this case, the non-negotiables were clear. The source business logic could not be modified. High-intrusion capture methods were undesirable. Extended downtime was out of scope. And the target architecture needed MongoDB to function as a serving layer for APIs and real-time services, not merely as a passive copy. At the same time, the pipeline itself needed to remain observable, restartable, and operationally understandable.
That immediately ruled out a large class of “just make it work” solutions. For example, periodic table scans might have been easier to prototype, but they would push too much load onto the source side and would not handle latency targets well. Direct application queries to AS/400 might solve the short-term product need, but they would externalize system risk into every future feature request. Trigger-heavy approaches could capture change accurately, but they would cross the intrusion line that operations teams were unlikely to accept.
The architecture therefore had to do three things at once:
-
treat IBM i as a protected system whose primary job was still transaction processing
-
extract changes with enough fidelity and continuity to support real-time downstream services
-
transform transaction-oriented tables into MongoDB data structures that were useful at the application layer
Each of those sounds manageable on its own. In combination, they force you to be precise about where complexity lives.
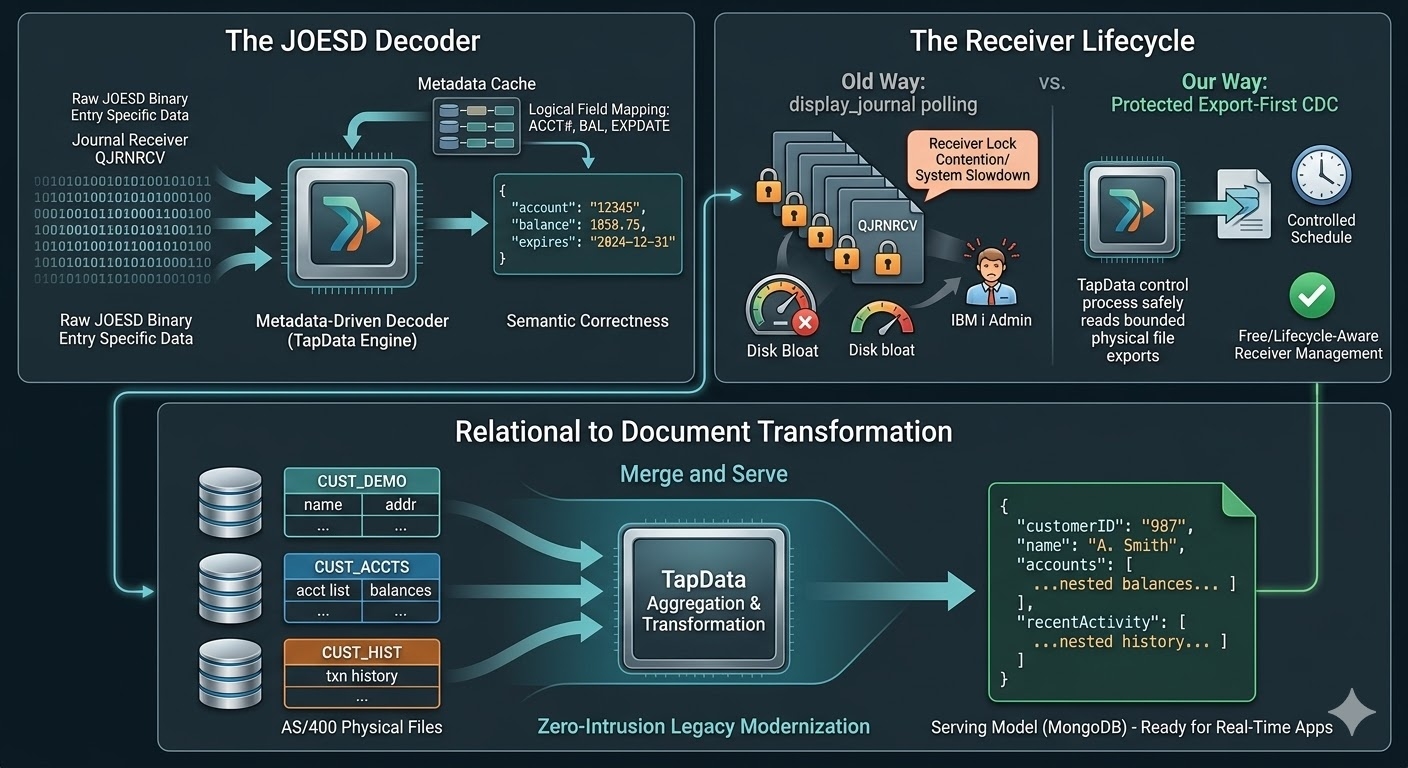
Challenge 1: Capturing Changes Without Turning the Journal Into a Production Risk
The first hard problem in low-intrusion Db2 for i CDC is not downstream modeling or sink design. It is much more fundamental:
How do you read the Journal without materially increasing CPU and I/O pressure on the IBM i host, without changing existing journaling behavior, without deploying a heavy source-side agent, and without creating new operational risk for the core system?
That question sounds straightforward until it is tested against production reality.
On IBM i, the Journal is the native and authoritative source of change. But that does not mean it behaves like a modern, developer-oriented change stream. Its design priorities are rooted in recovery, auditability, and system integrity. Those are exactly the properties that make it reliable — and also the reason it can be awkward to consume as a low-latency CDC feed.
Why the most obvious read path often fails in practice
A natural first approach is to read changes through native interfaces such as
QSYS2.DISPLAY_JOURNAL. It looks attractive for all the right reasons: no additional agent, no major installation work, and no need to alter existing application logic. In deployment terms, it appears minimally invasive.The problem is that minimal deployment intrusion does not automatically mean minimal production impact.
Under real workloads, this approach exposes several weaknesses at once. A single query can end up scanning large ranges of journal receiver data. Once that happens, latency becomes unpredictable and resource consumption rises quickly. Queries that look acceptable during a proof of concept may behave very differently against larger tables, higher transaction rates, or sustained polling. What seems like a simple read path starts to impose steady CPU and disk I/O pressure on a system whose primary job is still transaction processing.
That alone is enough to make
DISPLAY_JOURNAL a poor fit for serious low-latency CDC in many IBM i environments. But the more dangerous issue is not speed. It is receiver lifecycle interference.The receiver problem is not a corner case
Journal receivers are not just storage artifacts in the background. They are part of the operational heartbeat of the system.
In a typical environment, receivers rotate as they reach thresholds, are detached, and are later cleaned up. Any CDC design that interacts with journals continuously must coexist with that lifecycle cleanly. If it does not, it can turn from a read mechanism into a production problem.
This is where direct journal querying becomes risky. If an active reader still has a receiver effectively in use, automatic cleanup can fail. From the outside, this may look like a minor object-locking annoyance. In practice, it can grow into a storage-management issue, and eventually into a system-stability issue. Once old receivers stop being cleaned up as expected, the consequences accumulate quietly: more disk consumption, more journaling pressure, and more operational anxiety around a core system that nobody wants to destabilize.
That is why receiver handling deserves much more attention than it usually gets in abstract CDC discussions. In IBM i environments, a technically correct read mechanism is still the wrong mechanism if it disrupts normal receiver turnover.
Continuity across receiver switches must be designed explicitly
Even if performance were acceptable and lifecycle interference were not a concern, a production reader would still need to solve another difficult problem: receivers change.
They change when thresholds are reached. They change during manual operations. They change across system events. A CDC path that assumes a single continuous journal artifact is therefore fragile by design.
A reliable implementation needs to do at least four things:
-
detect when the currently attached receiver changes
-
follow the receiver chain automatically
-
continue without skipping any data
-
avoid rereading the same receiver range and producing duplicates
This is where the notion of source position becomes critical. On Db2 for i, continuity is not something that “comes with the connector.” It has to be maintained deliberately, often using a position model based on receiver identity plus sequence number. Without that, restart behavior becomes ambiguous and receiver transitions become dangerous.
A safer pattern: export first, then read externally
Once these constraints are taken seriously, the architecture shifts in a very practical direction.
Instead of treating the Journal like a stream to be queried continuously, a more stable pattern is to export bounded journal ranges into physical files and process those files externally.
This changes the shape of the source-side interaction in an important way. The IBM i host is no longer asked to support an always-on, downstream-sensitive read process. Its role is reduced to a bounded export step. The more expensive work — reading, parsing, decoding, queueing, and delivery — happens outside the critical path of the source runtime.
This is a much better fit for environments where the source system must remain protected.
It has several practical advantages.
First, it is genuinely low-intrusion in the production sense. No third-party CDC agent needs to be installed on the IBM i host. There is no need to alter application logic, enable a more invasive journaling strategy, or convert the system into something it was never meant to be.
Second, it keeps source-side work short and predictable. Exporting a bounded journal range is a much easier operation to reason about than maintaining a constantly active journal consumer whose load depends on downstream behavior.
Third, it lowers the organizational barrier to entry. In many companies, getting approval for a controlled export command plus outfile access is much easier than getting approval for deeper operational changes on a tightly governed IBM i environment.
Export is fast. The rest of the pipeline usually is not.
Moving to an export-first design solves one class of problems and immediately reveals another.
The export step itself can be surprisingly fast. But reading and decoding the exported files is not. That downstream work includes slower network I/O, binary payload extraction, operation classification, schema-aware parsing, and queue handoff. If all of this is handled in one linear worker, the pipeline may still “work,” but it will steadily fall behind as load increases.
That is why the design needs staged concurrency rather than a single all-in-one reader.
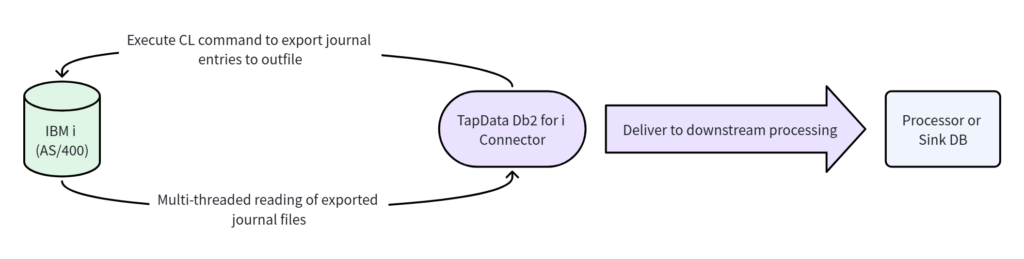
In practice, the implementation uses periodic CL commands on IBM i to export bounded journal ranges into physical outfiles, after which the exported files are read and parsed concurrently through JDBC. The export coordinator should remain ordered and conservative. One control thread advances through journal ranges in sequence and decides what gets exported next. That preserves a clean source-of-truth notion of progress. Its responsibility is limited to sequentially exporting journal entries into available outfile slots. In other words, the export side is responsible only for controlling read frequency and range, and for writing each journal slice to the next idle file in strict order.
The exported files, however, can be processed with more parallelism. Multiple outfile slots can be rotated so that export does not block on downstream reading. After each export completes, the file is handed off to downstream workers, while the export controller continues writing into the next available file. In the production design, eight outfile slots are enabled and reused in sequence. Each successful export submits a corresponding read-and-parse task to the worker side. Multiple worker threads can read completed outfiles concurrently. Because file reading involves network I/O and is significantly slower than the export operation, this parallelism is necessary to keep up with data generation. Using multiple rotating files allows export and file consumption to proceed in parallel instead of forcing the export stage to wait for remote reads to finish.
In the consumption stage, reader threads load journal entry data from the exported files and push it into an internal queue, where parsing workers continuously decode the entries into structured change events. Multiple reader threads are responsible for concurrently loading Journal Entry Data and sending it into designated queues. The number of reader threads and parser threads can be adjusted according to server capacity and live workload, so throughput can be tuned without changing the source-side export model. Each reader acts as a queue producer, and the parser workers act as queue consumers. To preserve ordering guarantees, each reader places the Journal Entry Data it has loaded into the assigned queue before parsing proceeds downstream.
The point is not to maximize parallelism everywhere. The point is to be explicit about where parallelism is safe and where ordered progression still matters. To guarantee continuity and fault tolerance, the pipeline records the Journal Sequence Number each time Journal Entry Data is processed successfully. If the task restarts, reading resumes from the last confirmed sequence number, which allows the pipeline to continue without breaking journal continuity.
The design becomes real only when restart continuity is solved
A CDC design is not production-ready until it can answer a simple operational question:
If the process stops in the middle of active traffic, where exactly does it resume?
On Db2 for i, the most reliable answer is usually a journal-based offset, typically anchored in sequence numbers.
Each time journal entry data is successfully processed, the pipeline records the corresponding position. On restart, processing resumes from the last confirmed point. That sounds routine, but it is what turns the design from an extraction trick into a recoverable data path.
Without explicit checkpointing, a restart means guesswork. With it, a restart becomes a controlled continuation.
That is the deeper lesson of the first challenge: low-intrusion CDC is not defined only by the absence of agents or triggers. It is defined by whether the source-facing path is bounded, whether receiver transitions are handled cleanly, and whether failures can be resumed from an exact position without ambiguity.
Challenge 2: Decoding Journal Entry Data Into Reliable Change Events
Once journal extraction is under control, the second challenge begins — and this is where the work becomes much more demanding than ordinary log consumption.
Exporting journal data into an outfile does not produce ready-to-use insert, update, and delete events. The most important payload is embedded inside
JOESD, the Journal Entry Specific Data field. This is where the actual record image lives. But it does not arrive in a convenient, self-describing event format. It arrives as IBM i–specific binary data whose meaning depends entirely on external metadata.At this point, the problem changes shape completely.
The question is no longer “How do we read the Journal?” It becomes:
How do we turn binary record images into trustworthy change events with correct field values, operation types, and source offsets?
That is the point where CDC stops being just data movement and becomes binary interpretation.
JOESD is not self-describing data
Many CDC systems condition engineers to expect some form of structured event envelope: field names, operation markers, maybe old and new values, perhaps a schema identifier. JOESD offers none of that convenience.
It is not text. It is not JSON. It is not a delimited record format. It does not contain its own field map.
Instead, it contains the raw binary record image of the journaled physical file. That means its interpretation depends on the layout of the source table: data types, field lengths, nullable fields, variable-length encoding, decimal storage format, and character encoding rules.
Without external schema metadata, JOESD is just a byte sequence.
This is what makes Db2 for i CDC feel fundamentally different from CDC on systems where logical change streams are easier to access. The Journal provides authoritative change history, but not a developer-friendly semantic layer on top of that history.
Operation classification is already more complex than it looks
Before decoding field values, the pipeline still has to determine what kind of event it is dealing with.
Different journal entry types correspond to different classes of record or transaction activity. Some represent data change. Some represent transaction control. Some can only be interpreted correctly if the journaling configuration is known — especially when distinguishing between after-image-only behavior and configurations that preserve both before and after images.
That means operation classification is not just a matter of checking a single field and mapping it to “insert” or “update.” It often requires combining entry type, payload structure, and journaling mode. The parser is not merely decoding data; it is reconstructing meaning from a set of lower-level signals.
The real complexity lies in the record layout
Once operation classification is underway, the hardest part begins: field-level interpretation.
IBM i physical file records are stored in tightly packed binary layouts. Fixed-length fields are placed at exact offsets. Variable-length fields may carry length markers. Nullable fields may depend on null bitmaps. Numeric values may be stored as packed decimal or zoned decimal rather than in formats more common in modern application code. None of that is visible unless the decoder knows exactly how the source schema is defined.
This means the parser must know, for each table it handles:
-
the order of fields
-
each field’s type
-
storage length
-
precision and scale for decimal values
-
nullability
-
CCSID or character handling expectations
-
offset rules for fixed and variable portions of the record
Only with that metadata can the raw bytes be turned into typed values.
That is why it is more accurate to describe this work as schema-aware binary decoding rather than simply “journal parsing.”
Building the decoder really means building a metadata-driven decoding subsystem
It is tempting to think of this challenge as writing one complex parser. In practice, that description is too small.
A reliable implementation needs a metadata-driven decoding subsystem with at least four responsibilities.
-
Collect current schema metadata
The decoder needs an up-to-date structural view of every journaled table. Field names, types, lengths, precision, nullability, and related properties have to be pulled from system metadata and cached in a form suitable for fast decoding.
Without a cached schema map, every decode path becomes both slower and more fragile.
-
Detect schema changes and refresh safely
A field added to the source table, a changed type, or an altered layout can invalidate parser assumptions immediately. If the metadata layer does not detect this and reload safely, the pipeline may continue emitting output that looks syntactically valid while being semantically wrong.
That is one of the most dangerous failure modes in CDC. Bad events can travel a long way before anyone notices that a field is shifted, truncated, misdecoded, or attached to the wrong semantic meaning.
-
Decode field values according to actual storage rules
Once JOESD is extracted, each field has to be interpreted according to its true on-disk representation:
-
character fields need byte-range extraction and trimming
-
packed decimals require custom unpack logic, including sign handling
-
zoned decimals follow different byte-level rules
-
binary integer fields can be mapped through direct buffer reads
-
null-capable fields require bitmap interpretation
-
variable-length values need correct length-prefix handling
This is slow, meticulous work. But it is the point where the system earns correctness.
-
Normalize the result into usable CDC events
Only after classification and field decoding can the pipeline emit the kind of structure downstream systems actually need.
A normalized event might look like this:
{
"op": "u",
"before": {"ID": 123, "NAME": "old", "AMOUNT": 100.50},
"after": {"ID": 123, "NAME": "new", "AMOUNT": 200.75},
"offset": {"seq": 1897730, "time": "2026-03-04", ...}
}
This is not what the Journal provides directly. It is what the decoding layer has to construct through metadata interpretation, binary unpacking, and operation classification.
Why self-parsing is difficult — and still often the right trade-off
There is no reason to romanticize this work. A production-grade decoder for Db2 for i journal payloads is a serious subsystem, not a utility function.
It has to handle schema acquisition, schema evolution, packed and zoned decimals, null bitmaps, character encoding issues, offset correctness, performance bottlenecks under load, and debuggability when any of those assumptions break.
That is exactly why implementation effort tends to grow quickly. A robust decoder can easily expand into a thousand-line-plus code path once real error handling, edge cases, metadata caching, and restart diagnostics are included.
And yet, despite that cost, there is a strong argument for owning this layer.
A self-controlled decoder allows the pipeline to emit consistent event shapes, introduce custom transformation logic, preserve raw payloads for debugging, and make schema evolution visible instead of opaque. It also avoids dependence on a black-box parser whose error modes may be hard to inspect when something goes wrong.
So the trade-off is real:
-
the implementation burden is high
-
the operational control is also high
In many systems that have to survive production scrutiny, that second point matters enough to justify the first.
Parsing accuracy matters more than implementation cleverness
It is easy to become fascinated with concurrency patterns, buffering strategies, or elegant abstractions in the parser implementation. Those are worthwhile, but they are not the primary success metric.
The real success metric is semantic correctness.
A single incorrect offset can corrupt a field quietly. A decimal decode bug can distort financial values without crashing anything. A schema mismatch can keep producing plausible-looking records that are subtly wrong. Those failures are more dangerous than obvious crashes because they preserve motion while destroying trust.
That is why the decoder must be designed not only to emit events, but also to support investigation. Raw payload preservation, source offsets, metadata version awareness, and enough traceability to explain a suspicious downstream record are all part of what makes a CDC parser operationally credible.
On Db2 for i, CDC decoding is not a secondary detail. It is the layer where raw change history becomes trustworthy application input.
Challenge 3: Turning Transaction-Oriented Tables Into a Document-Oriented Serving Model
Even after extraction and decoding are solved, the pipeline still faces a third challenge that is just as important as the first two.
The source system stores data in transaction-oriented physical files that behave like relational tables: normalized, flat, and optimized for operational updates. MongoDB is most useful in a very different way. Its strengths appear when related data can be assembled into documents shaped around business entities and application read paths.
That means the target-side problem is not simply “sync rows into another database.”
It is: how do we keep data from multiple transaction-oriented tables continuously assembled into service-ready MongoDB documents?
This is not only a modeling question. It is an incremental state-maintenance problem.
Raw table replication is rarely enough
A one-to-one replication model is often the first thing teams build. Each source table becomes a corresponding target collection, and change events keep those collections current.
That may satisfy the definition of replication, but it often fails the definition of usefulness.
Application teams rarely want a second copy of the same fragmentation that already exists in the source system. They do not want to reconstruct a business entity on every request by joining multiple replicated collections at read time. What they want is a serving model:
-
a customer view with profile data and derived indicators
-
an account view enriched with related records
-
a business-facing entity that can be served directly through APIs
-
a current-state document that is efficient to query in one read path
If the target simply mirrors source normalization, the system has moved data without solving the application problem.
That is why the document-model challenge deserves to be treated as a first-class engineering problem rather than a final formatting step.
The target is not a replica. It is a continuously maintained view
In this kind of architecture, MongoDB is most valuable not as a passive sink but as a serving layer.
The target document is often built from several upstream tables, and sometimes from several upstream systems. The result may take the form of a wide document, an incrementally maintained materialized view, or an entity-centric JSON structure optimized for application access.
This changes the design objective significantly. The target is no longer asked to preserve normalization. It is asked to preserve usefulness.
That may mean embedding related data, flattening selected attributes, or maintaining nested structures that make business sense even if they do not resemble the original relational design. MongoDB is a natural fit for this because it trades some redundancy for simpler and faster reads, which is exactly what service-oriented access layers often need.
Real-time merge is harder than “just joining tables”
Once this is acknowledged, the difficulty becomes clearer.
A target document built from multiple relational tables has to stay correct as source changes continue to arrive. Every event raises a new maintenance question:
-
if a parent row changes, which document fields must be updated?
-
if a child row is inserted, should it append to an embedded array or update a summary field?
-
if a child row is deleted, should it disappear from the document, remain historically visible, or trigger recomputation?
-
if several related events arrive close together, how is target consistency preserved incrementally?
This is why real-time document construction is not just replication plus joins. It is a stateful incremental merge problem.
The complexity is not limited to SQL logic. It extends into ordering, partial recomputation, cache design, and the question of how much derived state should be stored outside the final target document.
A practical pattern: build the full view once, then maintain it incrementally
A stable solution usually unfolds in two major phases.
Full-load phase
The initial target document model has to be built from a full dataset. The main table is copied first, then related tables are processed in order so that child data can be associated with the correct parent entities. This establishes a coherent baseline in MongoDB.
Without that baseline, incremental CDC logic has nothing stable to maintain.
Incremental phase
Once the initial documents exist, subsequent insert, update, and delete events can be applied as incremental maintenance operations. That is where the upstream CDC investment starts to pay off. Instead of rebuilding the entire target state repeatedly, the system updates only the affected parts of the document model as source changes arrive.
This is the difference between “batch reconstruction in a loop” and genuine real-time document maintenance.
Why a cache layer often becomes necessary
As soon as multiple related tables participate in one target document, a cache layer becomes hard to avoid.
The merge logic needs a place to hold association state outside the final document itself. A common pattern is to use a key-value structure where the key represents the association condition and the value stores related fragments or secondary data needed for assembly.
This serves two purposes at once.
First, it avoids expensive reassembly from scratch for every incoming change. Second, it gives the pipeline a stable intermediate model for incremental updates.
Without that intermediate state, the target document logic tends to collapse into repeated full recomputation, which quickly becomes expensive and fragile as relationships become more complex.
So the cache is not merely an optimization. It is part of the merge semantics.
The value of a real-time merge layer
At this point, the problem is no longer basic transport. It is the ability to:
-
synchronize multiple relational data sources
-
merge them into unified MongoDB documents
-
keep those documents updated in near real time
-
support multiple target shapes such as embedded subdocuments, embedded arrays, or flattened entity views
When a pipeline begins to maintain document-shaped entities derived from multiple relational tables, simple row-level replication quickly becomes insufficient. Each incoming change event must be interpreted in the context of the target document model. A single update may affect only one field, append a new element to an embedded array, or trigger recomputation of part of the document structure.
This is the point where a real-time merge layer becomes necessary. Instead of treating CDC events as isolated row mutations, the merge layer understands how those events affect the assembled document view. It applies incremental updates to the relevant parts of the document while preserving the consistency of the overall structure. In practice, this layer is responsible for maintaining the continuously updated document views that downstream applications actually consume.
In the Macau Resort deployment, this requirement became clear very quickly. Several operational datasets coming from the AS/400 systems were strongly related, but they were distributed across different physical files in Db2 for i. When those datasets were delivered into MongoDB, simply replicating them table by table did not produce structures that were useful for downstream services.
Application teams were not interested in rebuilding relationships at query time. What they needed were document-shaped entities that already reflected the relationships across those operational tables. That meant the pipeline had to do more than replay row-level events. It had to continuously assemble and maintain document structures derived from multiple sources.
At small scale, this kind of transformation can sometimes be implemented directly in application code or through ad-hoc processing logic. But as the number of source tables grows and the volume of change events increases, maintaining those document views becomes a separate responsibility inside the data pipeline itself.
In this project, that responsibility was handled through the real-time transformation and merge capabilities of TapData. Instead of treating MongoDB as a passive replication target, the pipeline maintained document-oriented views directly as change events arrived from the AS/400 journals. Updates from different relational tables were interpreted in the context of the target document model, allowing the system to update only the affected portions of a document rather than rebuilding it from scratch.
The result was not simply a synchronized copy of relational tables, but a continuously maintained set of entity-oriented documents derived from those operational datasets.
Replication and serving are different jobs
This is the conceptual distinction that matters most in the third challenge.
Teams often talk about “syncing data to MongoDB” as though it were one problem. In practice, it is usually two different problems layered together:
-
preserving source changes accurately
-
maintaining a target shape that is actually useful to downstream services
The first is a CDC problem. The second is a serving-model problem.
A pipeline can solve the first perfectly and still fail the second. It can be fast, stable, and technically impressive — yet still leave application teams with a target that is no easier to use than the original system.
That is why the third challenge matters so much. It is the point where data movement becomes data service.
And that is usually where the real value of the architecture is decided.
A Realistic Engineering Takeaway
The most useful lesson from this kind of project is not “legacy systems can be modernized.” That statement is too vague to help anyone.
A more useful takeaway is this:
When the source system is both critical and closed, the winning architecture is usually the one that externalizes complexity away from the source while preserving enough fidelity to build application-ready models downstream.
That is what the design here ultimately tried to do.
The IBM i host remained primarily a transaction system. Journal extraction was kept narrow and controlled. Heavy parsing work moved outward into systems that could scale and fail more safely. Schema interpretation became an explicit subsystem instead of an implicit assumption. And MongoDB was used not as a raw replica store, but as a document-serving layer shaped around downstream use cases.
The result is not a universal blueprint, because every IBM i environment carries its own operational constraints. But the pattern is broadly useful: protect the source, make offsets and metadata first-class, and treat document modeling as part of the pipeline, not something to improvise later.
Known Limitations and the Next Layer of Work
Even if this architecture is stable, it is not “done.”
Schema evolution remains one of the hardest long-term concerns. A parser that works perfectly against one schema version can become fragile when field definitions shift more often than expected. Derived document models also tend to grow in complexity over time as more downstream consumers arrive with slightly different requirements. At some point, teams have to decide whether to keep enriching a single serving model or introduce multiple derived views with clearer ownership boundaries.
There is also room to improve how the pipeline adapts to workload shape. Reader and parser parallelism can be tuned, but static tuning is rarely ideal forever. A more adaptive concurrency strategy could help the system respond better to uneven journal bursts, backfill windows, or temporary downstream pressure.
And then there is the perennial question behind all operational data systems: how much logic belongs in the pipeline, and how much belongs in application-specific serving layers? The right answer changes over time. That is normal. The point is not to avoid that evolution. It is to keep the pipeline understandable enough that evolution remains possible.
Closing Thought
IBM i systems tend to inspire extreme reactions: either they are dismissed as legacy baggage or romanticized as indestructible mainstays. Neither view is very helpful when you are actually responsible for integrating them.
From an engineering perspective, the more useful view is simpler. These systems continue to hold valuable operational truth. The challenge is not to force them into a modern shape they were never built for. The challenge is to design a boundary around them that lets modern systems consume that truth safely.
That is what makes this kind of work interesting. It sits at the point where data engineering stops being a matter of moving records and becomes a matter of respecting constraints.
And in real systems, constraints are usually where the design starts to get honest.

