
What is a Real-Time Updating Materialized View?
A materialized view is a data structure in database management systems that stores the results of a query as a physical table. This eliminates the need to re-run the query each time the view is accessed, improving query performance. Materialized views are especially useful for scenarios that involve frequent aggregation or complex joins, making them an effective data architecture pattern for improving performance and reducing resource usage.
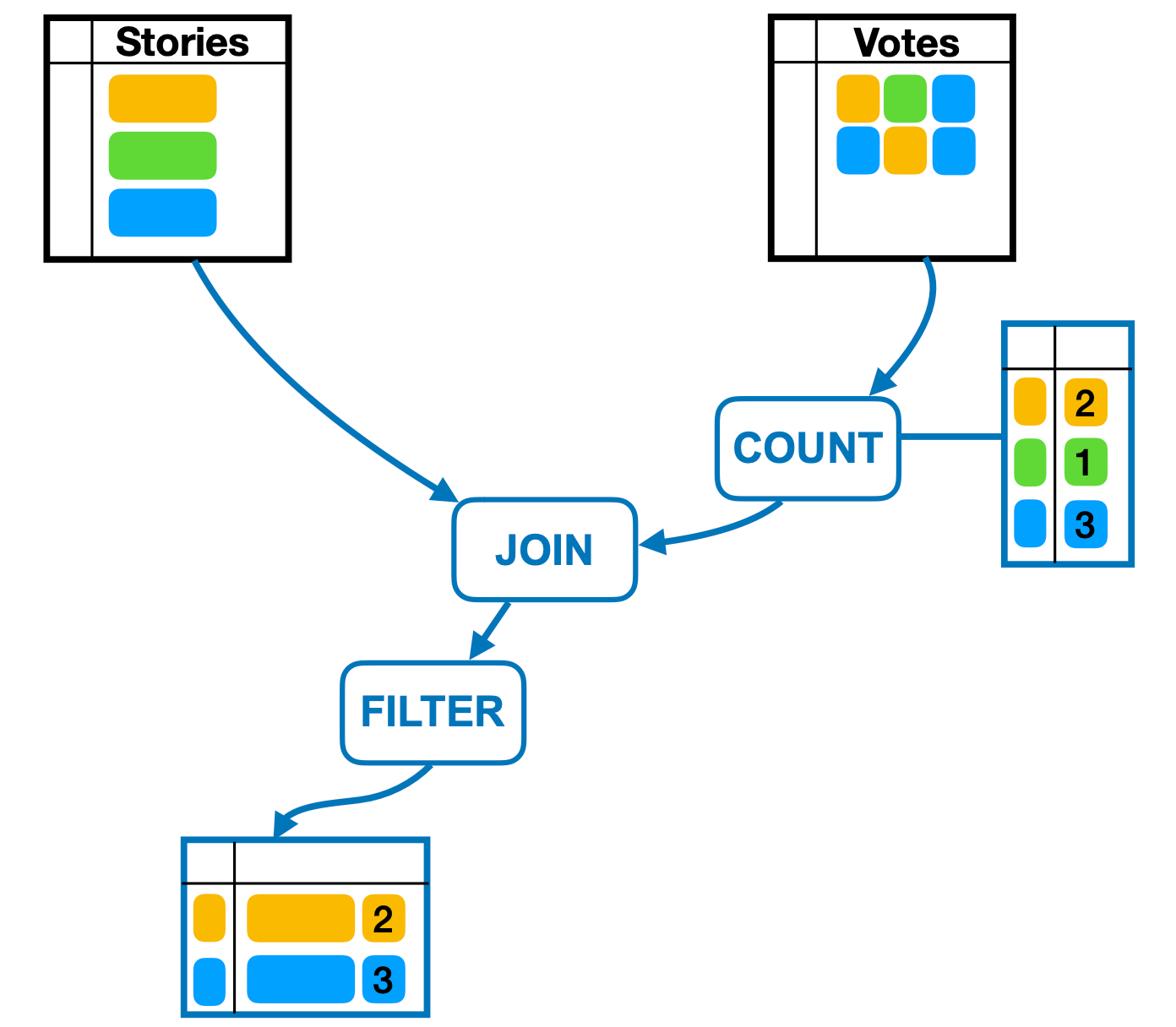
Based on the update strategy, materialized views can be categorized into two types: full updates and real-time (incremental) updates.
Full Updates
The full update strategy clears all existing data in the materialized view during each update and reinserts the latest query result set. This process can be understood as a combination of
TRUNCATE TABLE and INSERT INTO SELECT operations. While full updates are straightforward, they may become inefficient and resource-intensive in scenarios involving large data volumes or high-frequency updates.Real-Time (Incremental) Updates
The incremental update strategy is more efficient, as it calculates only the differences in the data that have changed since the last update and applies these changes to the materialized view. Incremental updates consume fewer resources while providing a more real-time data experience.
Scenarios for Real-Time Updates of Materialized Views
There are many business scenarios around us that require views to provide the current state, such as:
-
Balance Updates in Financial Transaction Systems
In financial systems, users’ account balances frequently change due to operations like deposits, withdrawals, transfers, and investments. To allow users to view their total account balance in real time after each transaction, real-time updated materialized views are typically used. This ensures users can immediately query the latest account status after executing a transaction.
Scenario Requirements:
-
Users can see balance changes in real time after a transaction is completed.
-
High data consistency with no delays.
Example:
-
A bank or stock trading platform updates the materialized view of a user’s account balance upon each transaction submission.
-
Real-Time Inventory in Inventory Management Systems
Real-time inventory management is critical for e-commerce platforms or warehouse systems. Sales, returns, and restocking must all be promptly reflected in the system to avoid overselling or stock shortages. Particularly when selling across multiple platforms, using multi-source aggregation and real-time updated materialized views ensures that users always see the latest inventory information after any inventory change.
Scenario Requirements:
-
Inventory information must be updated immediately after each sale or return.
-
Prevent overselling and ensure users see accurate inventory data during queries.
Example:
-
An e-commerce platform updates the inventory materialized view in real time after a user places an order, ensuring the inventory displayed on the front end and back-end management systems is synchronized.
-
Real-Time Monitoring and Alert Systems
In some production systems or IT monitoring platforms, monitoring metrics (such as CPU utilization, memory usage, and network traffic) change frequently. These systems need to determine whether to trigger alerts based on real-time data. Real-time update techniques can be used to constantly refresh materialized views of the metrics, enabling immediate detection of anomalies and triggering alerts.
Scenario Requirements:
-
Real-time monitoring of key system metrics.
-
Any anomalies must be detected and trigger the appropriate alert mechanisms as quickly as possible.
Example:
-
In an operations monitoring platform, the materialized view of monitoring metrics is refreshed each time new monitoring data is collected, ensuring alert rules are based on the latest data.
-
Real-Time Updates of User Behavior Data in Recommendation Systems
In e-commerce or content platform recommendation systems, user behavior (such as clicks, browsing, and purchases) has a real-time impact on recommendation results. To ensure the timeliness of recommendations, the system can update the materialized view in real time whenever user behavior data changes. This allows the recommendation system to generate content based on the latest user behavior data.
Scenario Requirements:
-
Frequent user behavior requires real-time adjustments to recommendations.
-
Data must reflect the user's latest interests and preferences in real time.
Example:
-
When a user clicks on a product or browses content, the materialized view of user behavior data is refreshed, enabling the recommendation system to adjust results in real time.
Let's use an example of an order-wide table to illustrate this implementation approach. We have a MySQL-based e-commerce platform, and we want to provide a comprehensive order API (including customer information, product details, logistics information, etc.) for customers to query on their mobile devices. Since MySQL has limitations in terms of concurrent queries and join performance, we choose to create a materialized view in MongoDB, which offers better query performance and supports JSON structures (API model design)
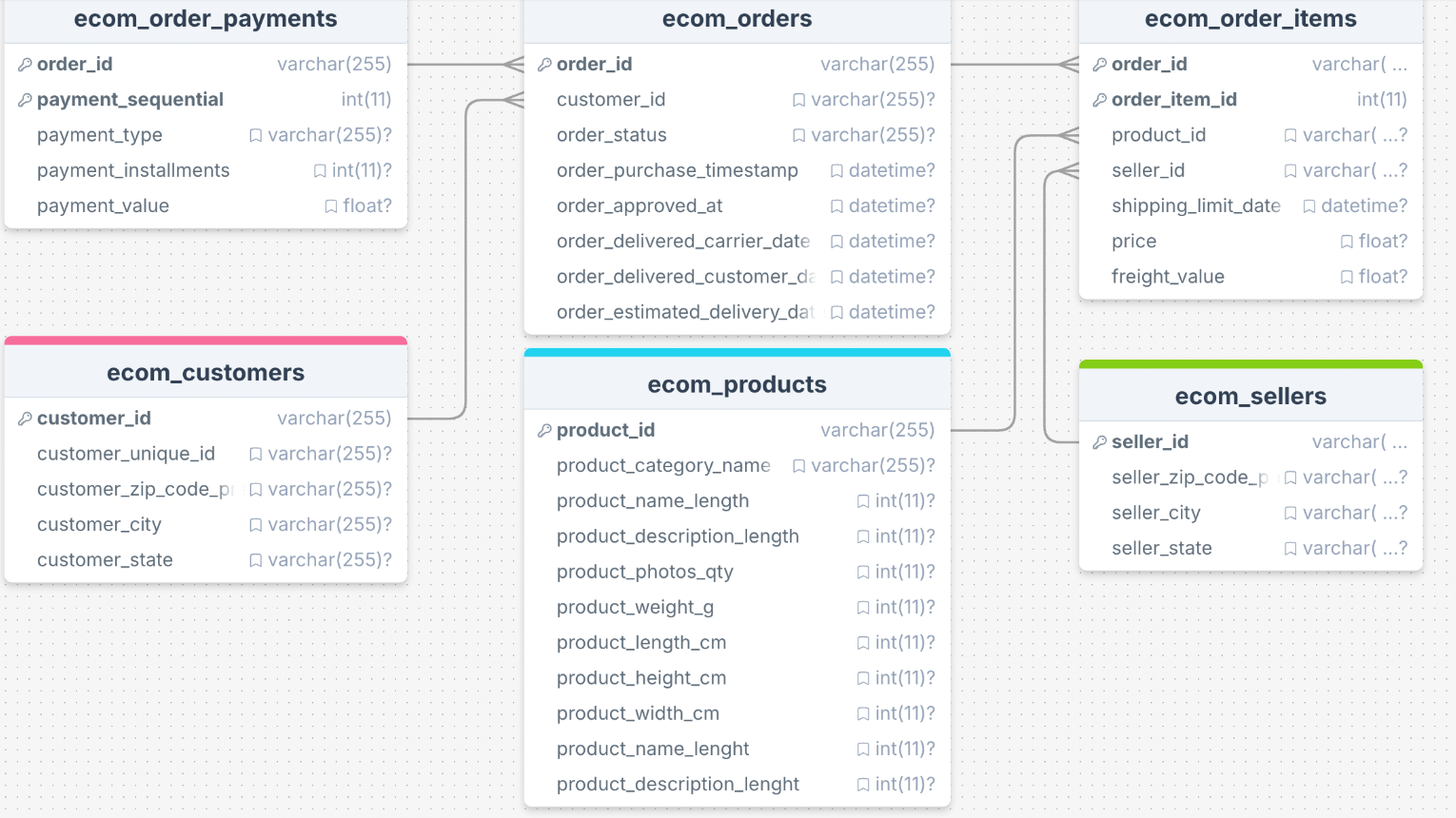
We want to have a view that can be directly used to query customer orders by
order_id or customer_id for the client. The API JSON structure might look like this, where a single model contains the order, customer address, payment information, and order details.{
"_id": ObjectId("66f7e633f72882271da1a2ec"),
"order_id": "0005a1a1728c9d785b8e2b08b904576c",
"customer_id": "16150771dfd4776261284213b89c304e",
"order_approved_at": "2018-03-20T18:35:21.000+00:00",
"order_delivered_carrier_date": "2018-03-28T00:37:42.000+00:00",
"order_delivered_customer_date": "2018-03-29T18:17:31.000+00:00",
"order_estimated_delivery_date": "2018-03-29T00:00:00.000+00:00",
"order_purchase_timestamp": "2018-03-19T18:40:33.000+00:00",
"order_status": "delivered"
customer_info: {
"customer_city": "santos",
"customer_id": "16150771dfd4776261284213b89c304e",
"customer_state": "SP",
"customer_unique_id": "639d23421f5517f69d0c3d6e6564cf0e",
"customer_zip_code_prefix": "11075"
},
order_items: [
{
"order_item_id": 1,
"price": 145.9499969482422,
"product_id": "310ae3c140ff94b03219ad0adc3c778f",
"order_id": "0005a1a1728c9d785b8e2b08b904576c",
"freight_value": 11.649999618530273,
"seller_id": "a416b6a846a11724393025641d4edd5e",
"shipping_limit_date": "2018-03-26T18:31:29.000+00:00",
"seller": {
"seller_city": "sao paulo",
"seller_id": "a416b6a846a11724393025641d4edd5e",
"seller_state": "SP",
"seller_zip_code_prefix": "03702"
},
"product": {
"product_category_name": "beleza_saude",
"product_description_lenght": 493,
"product_description_length": null,
"product_height_cm": 12,
"product_id": "310ae3c140ff94b03219ad0adc3c778f",
"product_length_cm": 30,
"product_name_lenght": 59,
"product_name_length": null,
"product_photos_qty": 1,
"product_weight_g": 2000,
"product_width_cm": 16
}
},
.........
]
}Introducing a powerful ETL tool that enables you to create CDC-based materialized views with just 10 lines of Python code!
TapFlow: A Powerful Tool for Building CDC-Based Materialized Views
What is TapFlow?
TapFlow is a newly launched programming API framework for the TapData Live Data Platform. It allows developers and data engineers to build data pipelines and models using a simple yet powerful programming language.
This release includes a Python SDK. TapFlow requires a connection to a TapData Cluster, which can be either the enterprise, cloud, or community version, to operate.
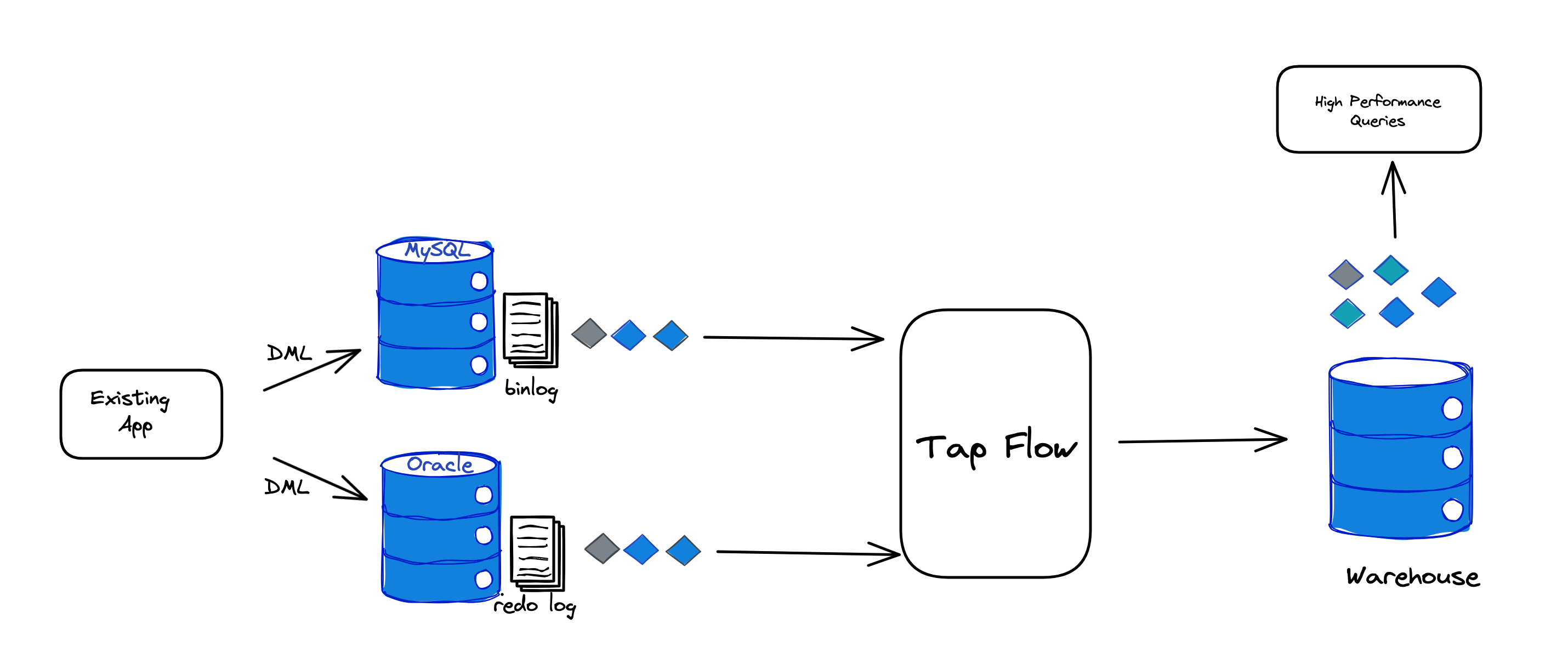
Building a Materialized View for Orders with TapFlow
Main steps:
-
Install TapFlow's Python SDK and CLI
-
Configure TapData Cluster connection details
-
Use TapFlow's commands and APIs to create a Flow to build real-time materialized view
-
Run the Flow
Detailed Steps:
Step 1: Install Tap Shell, a Python SDK and Interactive Command-Line Interface for TapFlow
# prerequisites: install python3 & pip3 before install tapshell
# Install TapShell using Pip
maximus@Reid:~/home pip3 install tapflowStep 2: Start and Configure Tap Shell
# Enter tapcli directory and Type tap and press enter button
maximus@Reid:~/ tap
Mon Nov 4 12:34:48 CST 2024 Welcome to TapData Live Data Platform, Enjoy Your Data Trip !
Tap Flow requires TapData Live Data Platform(LDP) cluster to run.
If you would like to use with TapData Enterprise or TapData Community, type L to continue.
If you would like to use TapData Cloud, or you are new to TapData, type C or press ENTER to continue.
Please type L or C (L/[C]): C
You may obtain the keys by log onto TapData Cloud, and click: 'User Center' on the top right, then copy & paste the accesskey and secret key pair.
Enter AK: xxxxxxxxxxxxxxxxxxx
Enter SK: xxxxxxxxxxxxxxxxxxx
Mon Oct 21 15:53:50 CST 2024 connecting remote server: https://cloud.tapdata.net ...
Mon Oct 21 15:53:50 CST 2024 Welcome to TapData Live Data Platform, Enjoy Your Data Trip !
========================================================================================================================
TapData Cloud Service Running Agent: 1
Agent name: agent-jk6453h (Machine), ip: 192.168.1.11, cpu usage: 40%
tap >
# If you're using TapData Enterprise then type L, please provide the server URL with port and access code, for example: 192.18.108.1:13030 && 123e4567-e89b-12d3-a456-426614174000. You can find the access code by logging into the TapData Enterprise platform, then navigating to Account Settings
Mon Nov 4 12:34:48 CST 2024 Welcome to TapData Live Data Platform, Enjoy Your Data Trip !
Tap Flow requires TapData Live Data Platform(LDP) cluster to run.
If you would like to use with TapData Enterprise or TapData Community, type L to continue.
If you would like to use TapData Cloud, or you are new to TapData, type C or press ENTER to continue.
Please type L or C (L/[C]): L
Please enter server:port of TapData LDP server: 127.0.0.1:3030
Please enter access code: xxxxxxxxxxxxxxxxxxxxxxxxxx
Mon Oct 21 11:26:55 CST 2024 connecting remote server: you 127.0.0.1:3030 ...
Mon Oct 21 11:26:55 CST 2024 Welcome to TapData Live Data Platform, Enjoy Your Data Trip !
tap > Step 3: Start Building Materialized View
Step 3.1: Set Up Connection with Source databases.
# Connect with Source Database Mysql
tap > mysqlJsonConfig = {
'database': 'Demo',
'port': 3306,
'host': 'demo.tapdata.io',
'username': 'demouser',
'password': 'demopass'
};
tap > mysqlConn = DataSource('mysql', 'qa_mySqlEcommerceData', mysqlJsonConfig)
.type('source')
.save();
datasource qa-mySqlEcommerceData creating, please wait...
save datasource qa-mySqlEcommerceData success, will load schema, please wait...
load schema status: finished
Upon successful signup on https://view.tapdata.io/, TapFlow automatically provisions a managed MongoDB Atlas instance
for the user. This instance, referenced by the DEFAULT_SINK variable, serves as the
destination for materialized views or tables created from source databasesStep 3.2: Create data pipeline to build wide order data model
# Create the flow and set the base or master table "ecom_orders"
tap> orderFlow = Flow("Order_SingleView_Sync").read_from("qa_mySqlEcommerceData.ecom_orders");
Flow updated: source added
# Lookup and add the 'ecom_customers' table as an embedded document in 'orders' using customer_id as the association key.cIn MongoDB, path="customer_info", embeds it with the field name customer_info, and type="object", indicating it will be stored as an embedded document.
tap> orderFlow.lookup("qa_mySqlEcommerceData.ecom_customers", path="customer_info",
type="object", relation=[["customer_id","customer_id"]]);
Flow updated: source added
Flow updated: new table added as child table
# Lookup and add the 'ecom_order_payments' table as an embedded array in 'orders' using order_id as the association key. In MongoDB, path="orderPayments" embeds it with the field name order_payments, and type="array", indicating it will be stored as an embedded array.
tap> orderFlow.lookup("qa_mySqlEcommerceData.ecom_order_payments", path="order_payments",
type="array", relation=[["order_id","order_id"]]);
Flow updated: source added
Flow updated: new table added as child table
# Lookup and add the 'ecom_order_items' table as an embedded array in 'orders' using order_id as the association key. In MongoDB, path="order_items," embeds it with the field name order_items, and type="array", indicating it will be stored as an embedded array.
tap> orderFlow.lookup("qa_mySqlEcommerceData.ecom_order_items", path="order_items",
type="array", relation=[["order_id","order_id"]]);
Flow updated: source added
Flow updated: new table added as child table
# Lookup and add the 'ecom_products' table as embedded document in 'order_itmes' using product_id as association key.
tap> orderFlow.lookup("qa_mySqlEcommerceData.ecom_products", path="order_items.product",
type="object", relation=[["order_items.product_id","product_id"]]);
Flow updated: source added
Flow updated: new table added as child table
# Lookup and add the 'ecom_sellers' table as embedded document in 'order_itmes' using seller_id as association key.
tap>orderFlow.lookup("qa_mySqlEcommerceData.ecom_sellers", path="order_items.seller",
type="object", relation=[["order_items.seller_id","seller_id"]]);
Flow updated: source added
Flow updated: new table added as child table
# Write data to target Monogdb
tap> orderFlow.write_to(DEFAULT_SINK.orderSingleView).save();
# Start the pipline
tap> orderFlow.start();
# view Flow stats
tap> stats 'Order_SingleView_Sync' 
Step 3.3. View Wide Order Data model in MongoDB
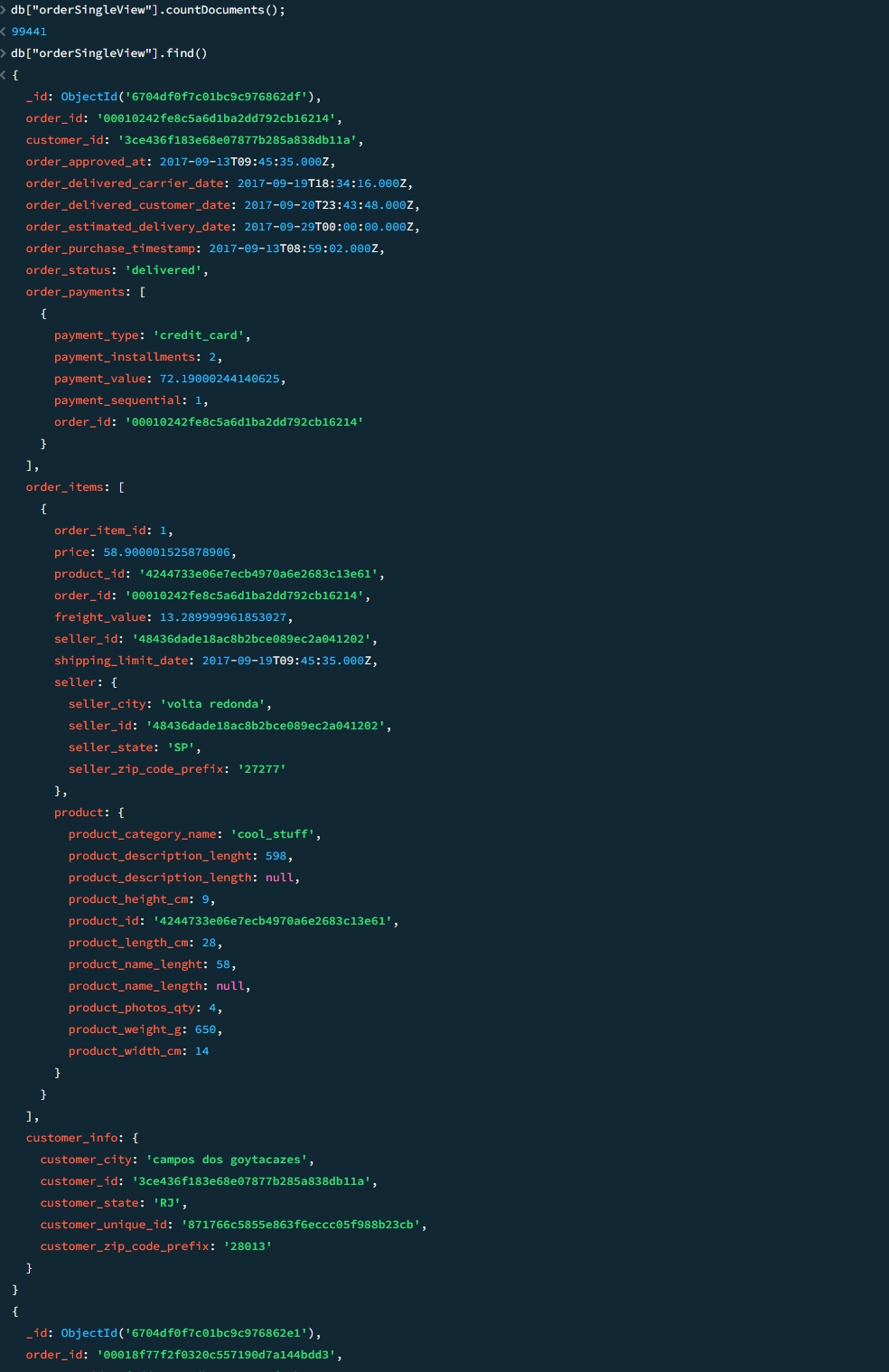
Verify the Real-Time Update Effect of the Materialized View
-
Login to Mysql Server
-
Use ECommerceData;
-
select count(*) from ecom_orders eo;
-
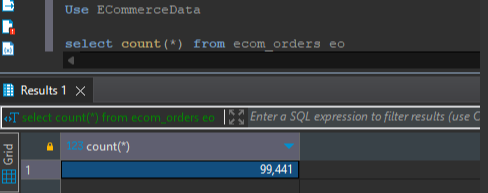
Execute the following script to add new records in the ecom_orders table:
DELIMITER //
CREATE PROCEDURE InsertRandomOrders()
BEGIN
DECLARE i INT DEFAULT 0;
-- Disable foreign key checks
SET FOREIGN_KEY_CHECKS = 0;
WHILE i < 10 DO
INSERT INTO ECommerceData.ecom_orders
(order_id, customer_id, order_status, order_purchase_timestamp,
order_approved_at, order_delivered_carrier_date,
order_delivered_customer_date, order_estimated_delivery_date)
VALUES
(
CONCAT('ORD_I_', UUID()), -- Adds 'ORD_' before the randomly generated order_id
UUID(), -- Generates a random customer_id
CASE
WHEN RAND() < 0.3 THEN 'delivered'
WHEN RAND() < 0.6 THEN 'shipped'
ELSE 'processing'
END, -- Random order status
NOW() - INTERVAL FLOOR(RAND() * 365) DAY, -- Random order purchase date within the last year
NOW() - INTERVAL FLOOR(RAND() * 300) DAY, -- Random approved date within the last 300 days
NOW() - INTERVAL FLOOR(RAND() * 200) DAY, -- Random carrier delivery date within the last 200 days
NOW() - INTERVAL FLOOR(RAND() * 100) DAY, -- Random customer delivery date within the last 100 days
NOW() + INTERVAL FLOOR(RAND() * 30) DAY -- Random estimated delivery date within the next 30 days
);
SET i = i + 1;
END WHILE;
-- Re-enable foreign key checks
SET FOREIGN_KEY_CHECKS = 1;
END
//
DELIMITER ;
CALL InsertRandomOrders();select count(*) from ecom_orders eo;
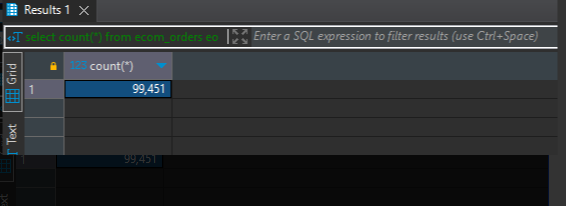
-
Observe the Mongodb wide Order View Table
-
Run the query below to check the total number of orders in MongoDB, which should now be 99,451, as we added 10 new records. Before adding the records through the script, the total was 99,441.
-

-
Update customer city: Change the city name by adding "CITY_" as prefix in it.
-
Please execute the following script to update and add prefix in city_name in ecom_customer table:
-
DELIMITER //
CREATE PROCEDURE UpdateCustomerCity()
BEGIN
-- Disable autocommit
SET autocommit = 0;
-- Update customer_city by adding the prefix 'CITY_' for the specified customer_ids
UPDATE ECommerceData.ecom_customers
SET customer_city = CONCAT('CITY_', customer_city)
WHERE customer_id IN (
'00012a2ce6f8dcda20d059ce98491703',
'000161a058600d5901f007fab4c27140',
'0001fd6190edaaf884bcaf3d49edf079',
'0002414f95344307404f0ace7a26f1d5',
'000379cdec625522490c315e70c7a9fb',
'0004164d20a9e969af783496f3408652',
'000419c5494106c306a97b5635748086',
'00046a560d407e99b969756e0b10f282',
'00050bf6e01e69d5c0fd612f1bcfb69c',
'000598caf2ef4117407665ac33275130'
);
-- Commit the transaction to save the changes
COMMIT;
-- Re-enable autocommit
SET autocommit = 1;
END
//
DELIMITER ;
call UpdateCustomerCity()-
Verify the updates in the
customer_infodocument within the MongoDB wide collection.
db.orderSingleView.findOne({"customer_info.customer_id": "00012a2ce6f8dcda20d059ce98491703"})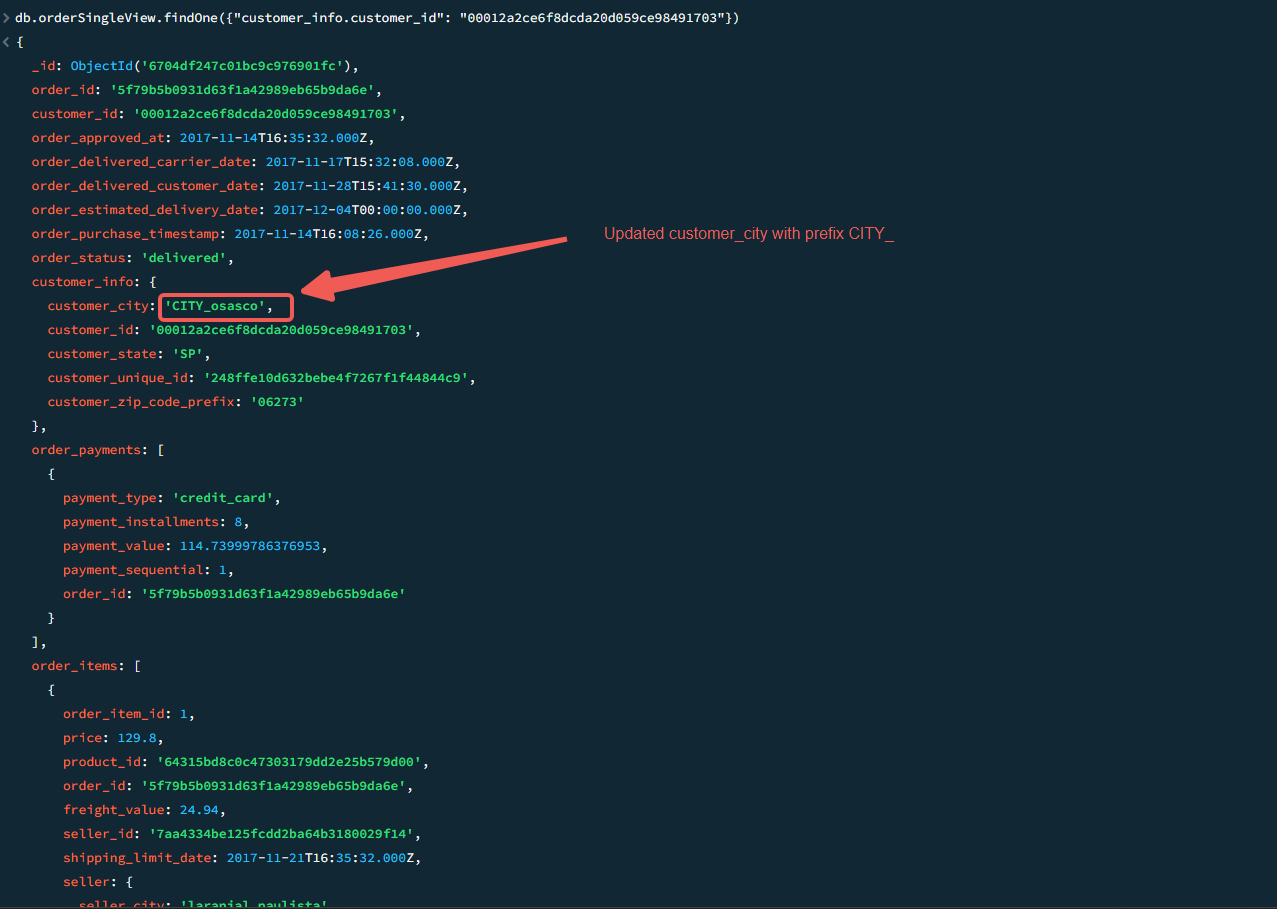
Summary
TapFlow is a programming framework currently in its preview stage. It lets you create real-time data replication, process data, and build materialized views. TapFlow includes APIs, a Python SDK, and the Tap CLI tool. It works with a TapData Cluster, which you can get by signing up for a TapData Cloud account or deploying TapData Enterprise or Community locally. For details about TapFlow, check the TapFlow documentation. For TapData product information, visit: https://docs.tapdata.io.
Experience Real-Time Materialized Views with TapView
Leverage CDC-powered materialized views to keep your data always fresh and unified. TapView streamlines complex workflows like multi-table merging and real-time updates, enabling high-performance queries and actionable insights—all with minimal effort.

