
V 2.0
In the ever-evolving landscape of customer support, managing support tickets efficiently can be likened to navigating through a dense forest. Traditional methods are akin to walking through this forest with a flashlight—limited and often slow. However, integrating advanced AI technologies like Large Language Models (LLMs) and Retrieval-Augmented Generation (RAG) is akin to navigating the forest with a GPS and a searchlight—fast, accurate, and efficient.
In this blog, I’ll share how incorporating LLMs and RAG technology using Tapdata Cloud and MongoDB Atlas can revolutionize real-time support ticket processing in an enterprise setting. This approach not only enhances efficiency but also ensures that customer queries are resolved with unprecedented accuracy and speed.
Why LLMs and RAG?
LLMs are designed to understand and generate human-like text. However, they often struggle with providing precise answers to specific queries, especially when dealing with specialized or up-to-date information. This is where RAG comes into play. RAG bridges this gap by incorporating real-time data retrieval into the response generation process, ensuring that the information provided is both accurate and current.
Implementing the Solution
To implement this powerful solution, just perform these steps:
-
Set Up Tapdata Cloud and MongoDB Atlas
Start by setting up Tapdata Cloud to collect real-time incremental data from your various relevant databases with data used for support. Next, set up MongoDB Atlas, which offers vector search capabilities essential for efficient data retrieval.
-
Prepare Real-Time Vector Data
In Tapdata Cloud, prepare real-time vector data by converting support ticket descriptions into vector representations. Store these vectors in MongoDB Atlas, allowing for fast and relevant search results.
-
Retrieve and Process Data
Use MongoDB Atlas to retrieve the most relevant support tickets based on user queries. Employ Python scripts to execute vector queries and return relevant historical work orders and solutions.
>>> For more specific and detailed instructions, see TapData Quick Start.
Example Use Case: Support Ticket Processing
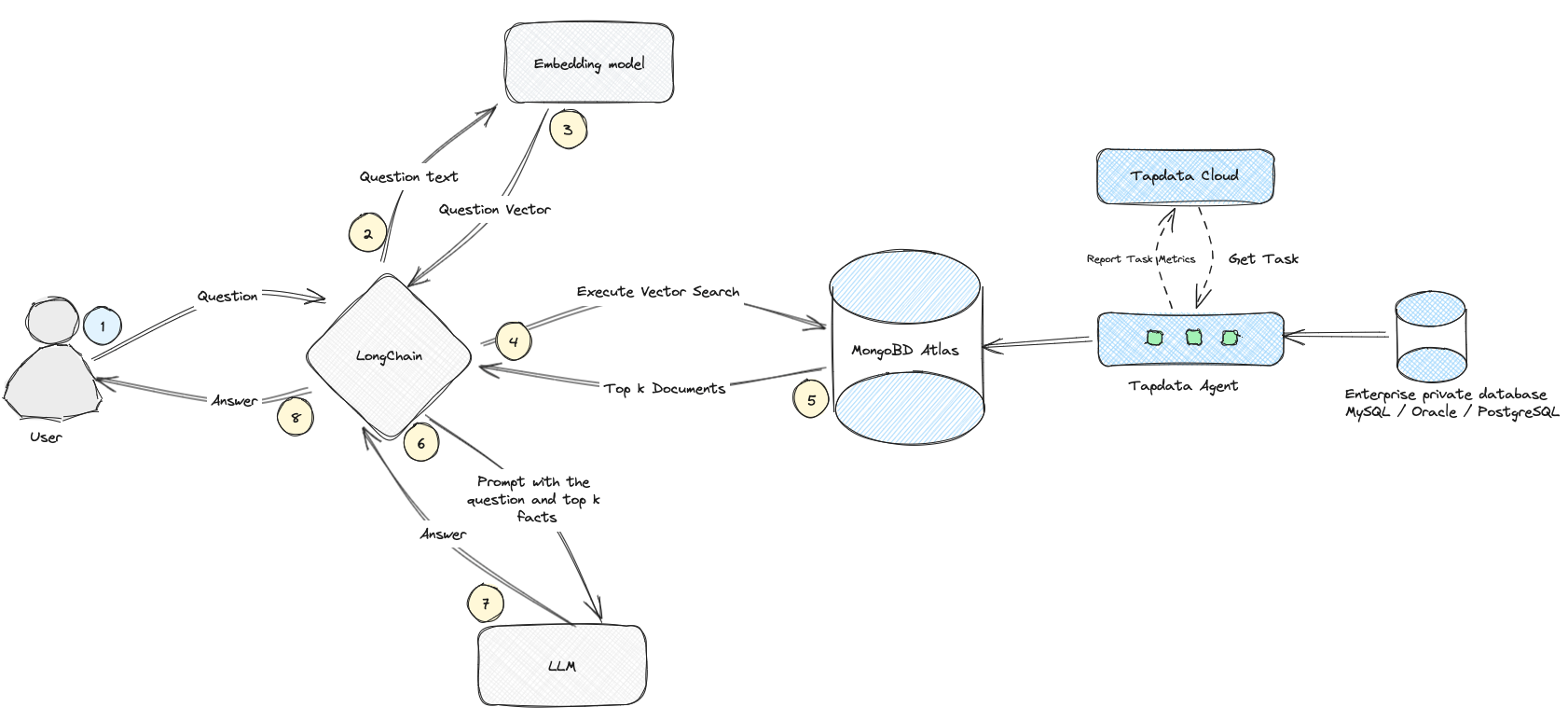
To illustrate the power of RAG, let's consider a common scenario: a user needs to reset their account password. The process follows these steps:
-
User Query: The user asks, "How do I reset my account password?".
-
Question Handling: The system captures the question and sends it to the LongChain, which is a key component that bridges the gap between user queries and the AI system's response generation.
-
Vectorization: LongChain uses an embedding model to convert the question into a vector representation.
-
Vector Search: This vector is used to search the MongoDB Atlas database.
-
Document Retrieval: MongoDB Atlas retrieves the top relevant documents (support tickets and solutions) based on the search.
-
Query Augmentation: LongChain combines the question with the retrieved documents to create a detailed prompt.
-
Answer Generation: The prompt is sent to an LLM, like the Google Gemma model, to generate a detailed answer.
-
User Response: The system sends the generated answer back to the user.
By using RAG, support ticket processing becomes more efficient and accurate. This approach leverages advanced AI to quickly retrieve and generate relevant information, enhancing user satisfaction and operational efficiency.
In this article, we will focus on steps 3 to 5, which involve using MongoDB Atlas for data preparation. Here’s how you can prepare vector data for work orders:
-
Log in to TapData Cloud.
-
Create a TapData Agent.
-
Log in to the MongoDB Atlas console and create a MongoDB Atlas database.
-
Create a connection to the source database (enterprise private database, MySQL, Oracle, or SQLServer).
-
Create a connection to the target database (MongoDB Atlas).
-
Create a data synchronization task from the source database to the target database and add a data vectorization processing node.
-
Log in to the MongoDB Atlas console and create a MongoDB Atlas Vector Index.
-
Use Python to execute vector queries and return the most relevant historical work orders and solutions.
Preparation
Before we begin, we need to prepare a few accounts: TapData Cloud, MongoDB Atlas, and Hugging Face:
-
TapData Cloud: Real-time collection of incremental data from business databases, supporting over 20 common RDBMS or NoSQL databases such as MySQL, SQLServer, Oracle, PostgreSQL, and MongoDB, with second-level data latency.
-
MongoDB Atlas: An open-source document database known for its flexibility and ease of use. MongoDB Atlas (v6.0.11, v7.0.2) provides vector search capabilities, supporting generative AI applications.
-
Hugging Face Access Token: In this example, we use Hugging Face's Embedding Model service to vectorize text. You can also use models from other platforms or locally deployed models.
Creating a TapData Agent
-
Log in to the TapData Cloud console. For the first-time login, follow the onboarding guide.
-
Select your application scenario. Choose "Moving data into MongoDB Atlas" and click [Next].
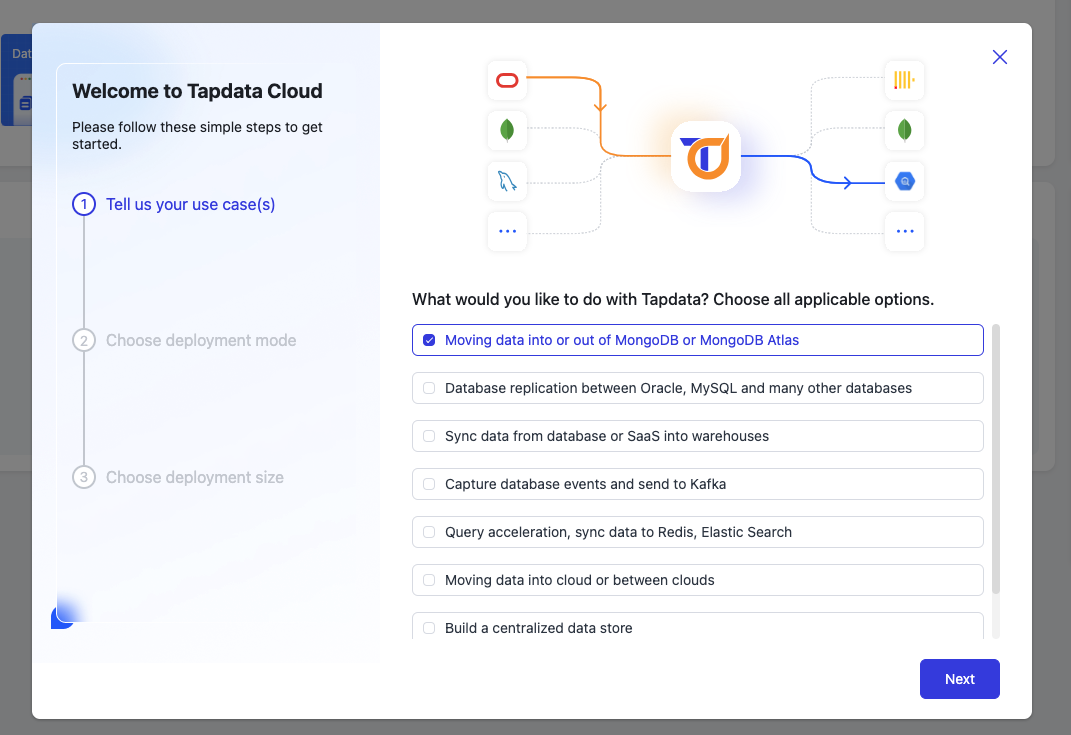
-
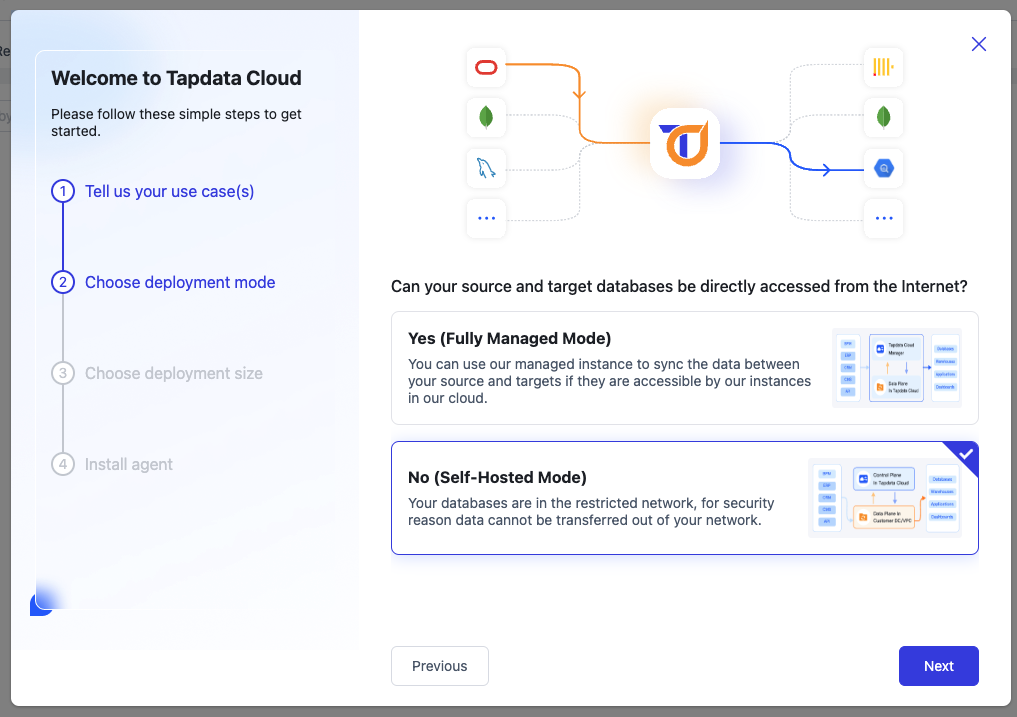
In the second step, choose the deployment method based on the location of your data source:
-
Fully Managed Mode: The task runs in the cloud and requires public internet access to your database. If your database allows public access, this mode is more convenient.
-
Self-Hosted Mode: Deploy the Agent within the local network (LAN) or VPC where your database is located, and ensure public internet access for the Agent to connect with TapData Cloud. The task will connect to your database via the LAN.
Since I am using a local private database, I will choose the self-hosted instance and then click [Next].
-
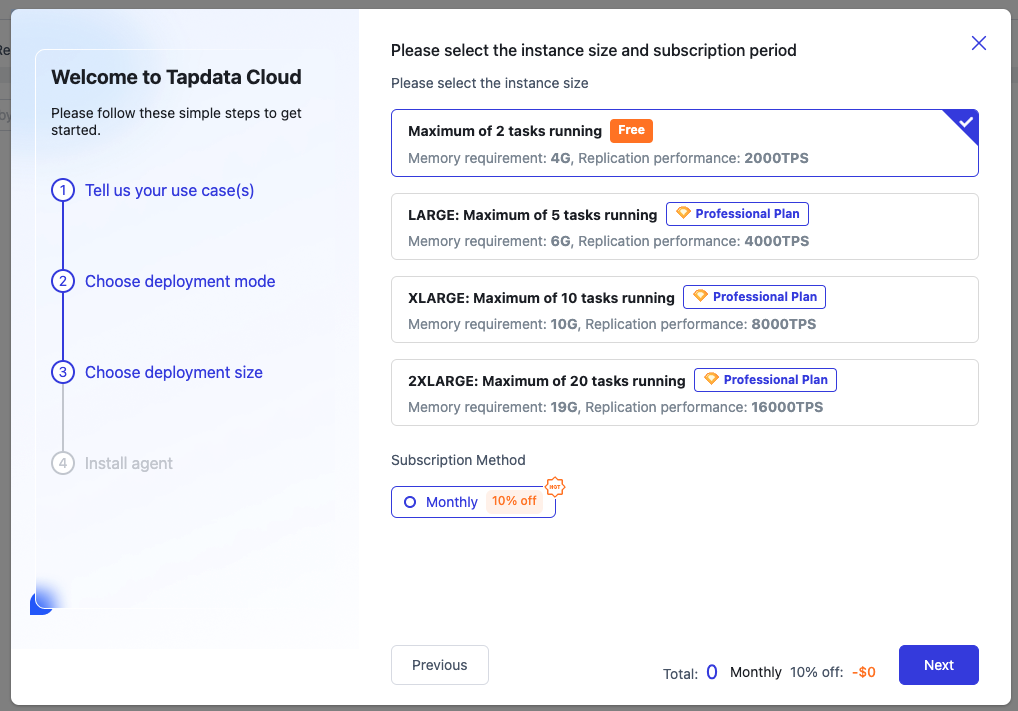
For the third step, choose deployment size. Here, we'll select the free instance option and click [Next].
-
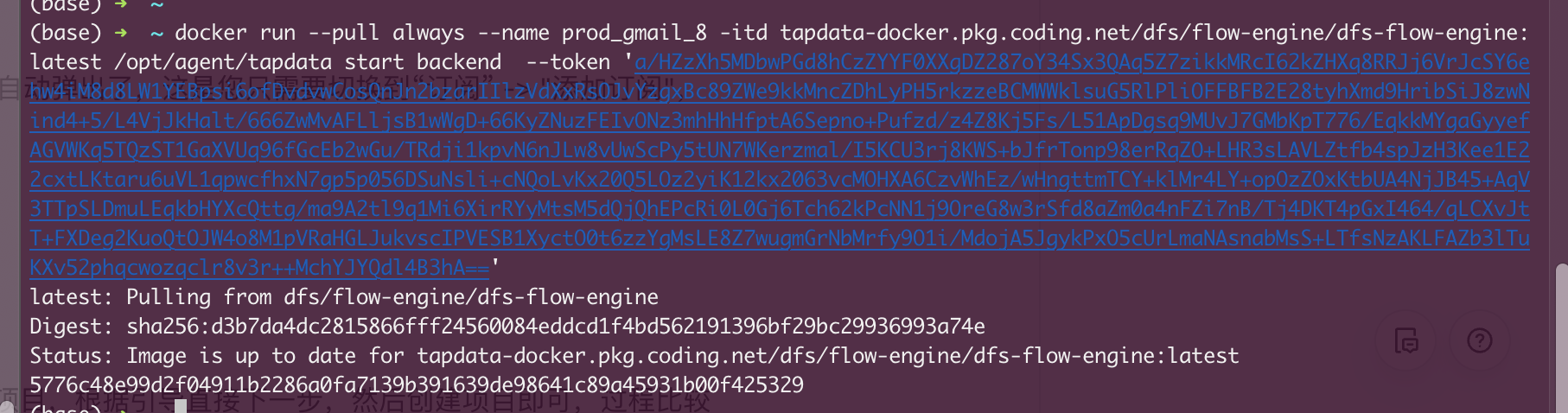
Moving on to the fourth step, we'll install and deploy the Agent. We'll use Docker containers for this deployment method. Click the [Copy] button to copy the startup command and paste it into your local computer to execute (ensure Docker software is pre-installed; refer to Docker Desktop for installation instructions).
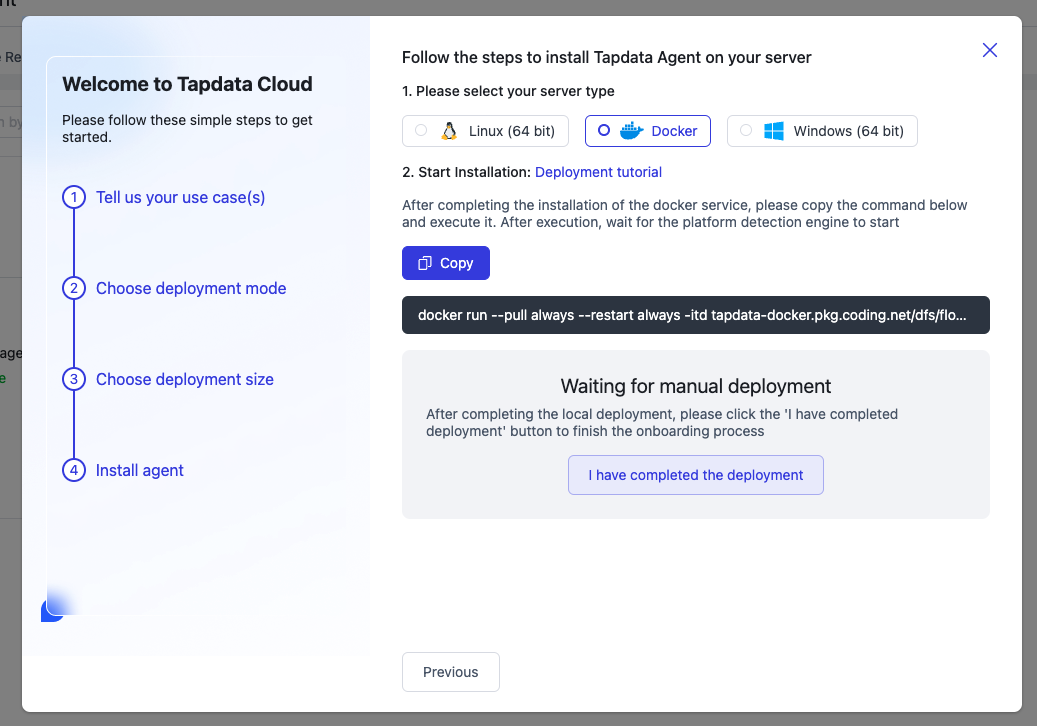
-
After executing the startup deployment command locally, wait a few minutes until the instance status changes to "Running" before proceeding.
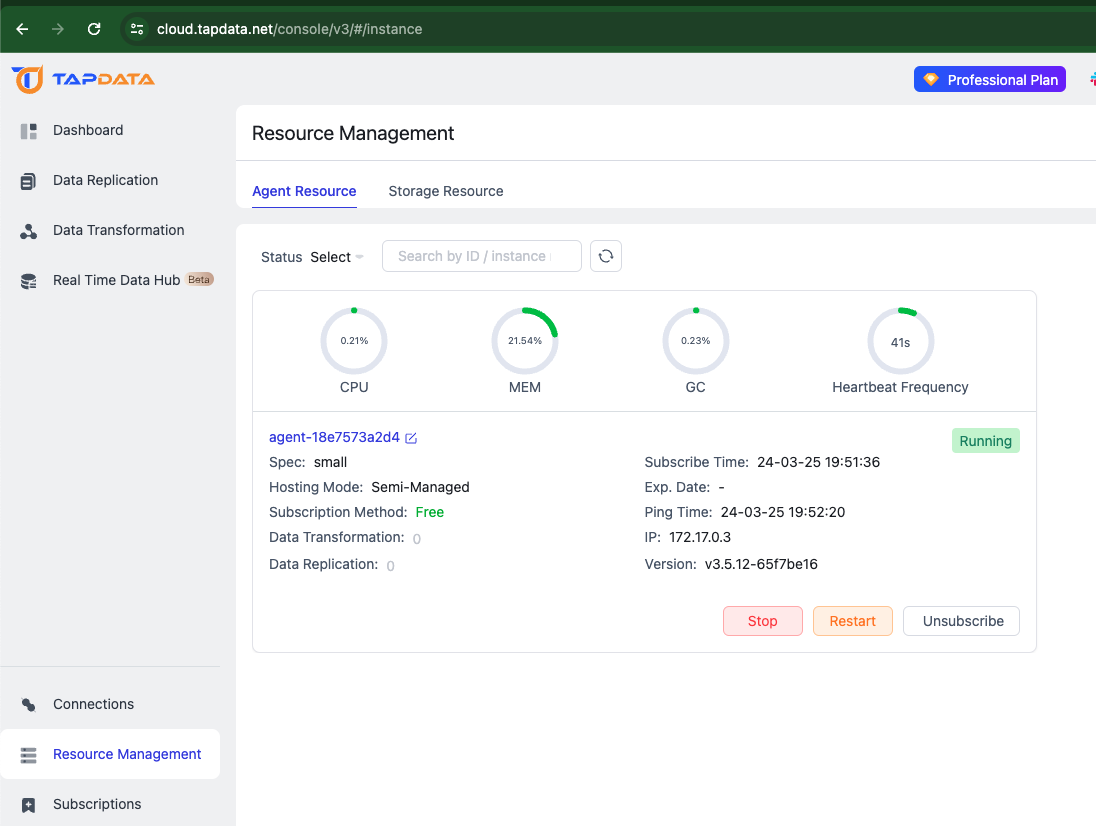
At this stage, the Agent is prepared for running data synchronization tasks. If you've completed the onboarding process previously, it won't automatically appear upon logging in again. Simply switch to "Subscription" -> "Add Subscription", choose your deployment method and specifications, create an instance, and complete the deployment.
Creating a MongoDB Atlas Database
-
Upon logging in to Mongo DB Atlas, click on [New Project] to initiate project creation. Follow the prompts and proceed to create the project; the process is straightforward.
-
Within the newly created project, click on [+Create] to establish a MongoDB Database.
-
Opt for the M0 specification, retaining the default name "Cluster-0" for the cluster. Choose Google Cloud as the provider and select Taiwan as the region. Click [Create Deployment] to proceed.
-
Add an account for accessing the database.
-
Opt to connect to MongoDB Database using [Drivers].
-
Choose Java as the driver, then copy the connection string and save it.
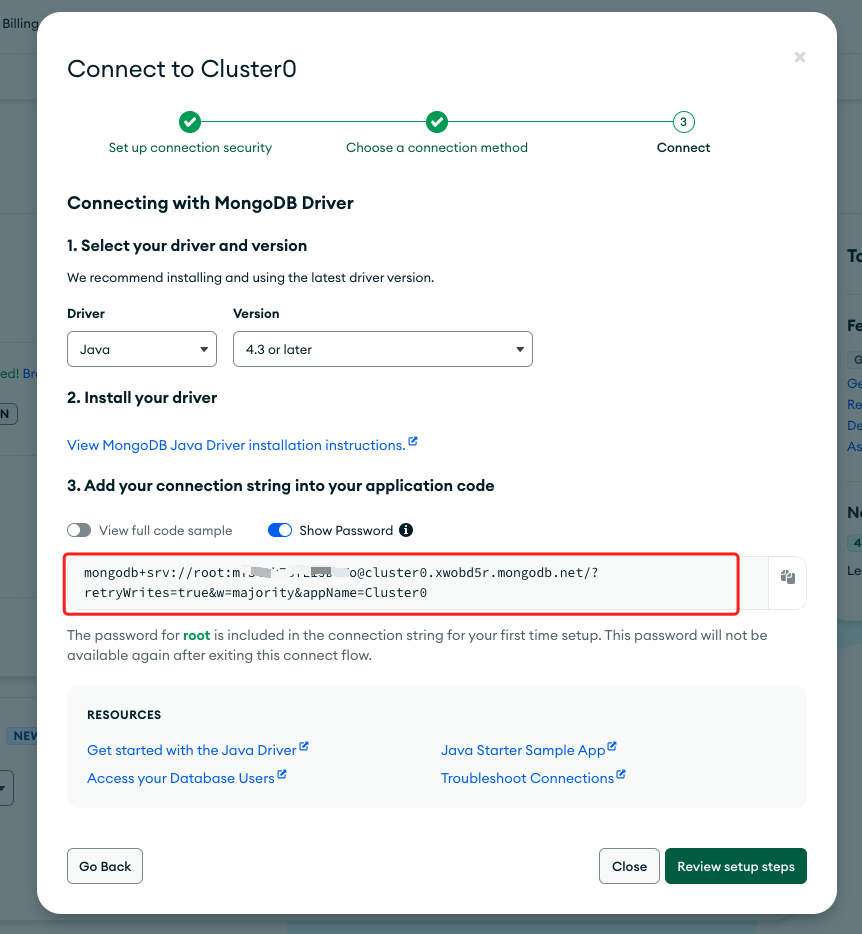
-
Add the Network Access whitelist by selecting "Add (IP) Address".
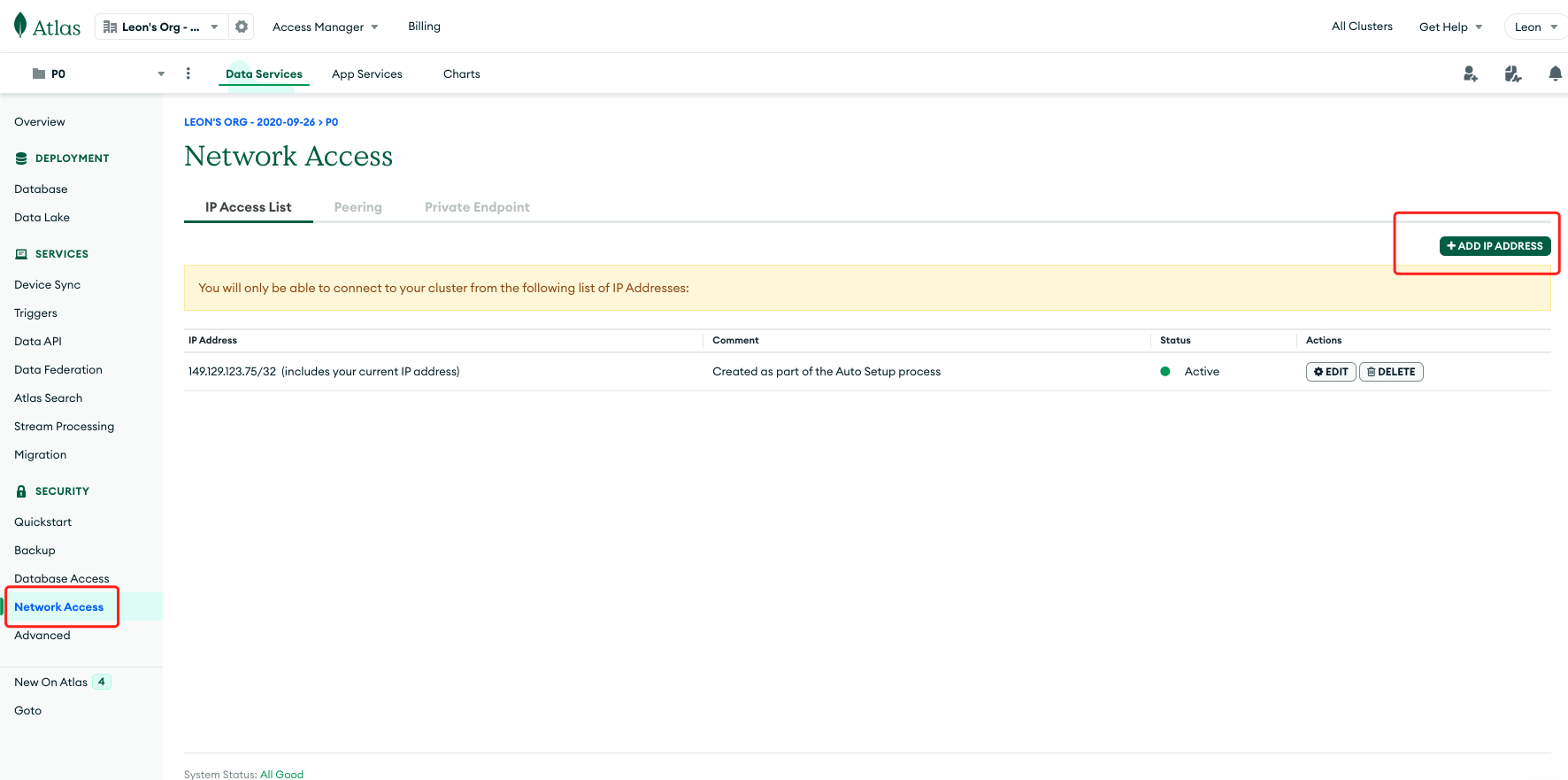
-
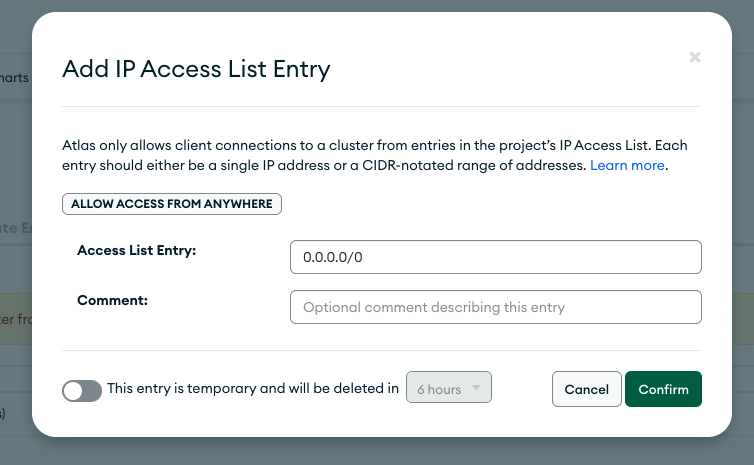
For demonstration purposes, set it to allow access from anywhere.
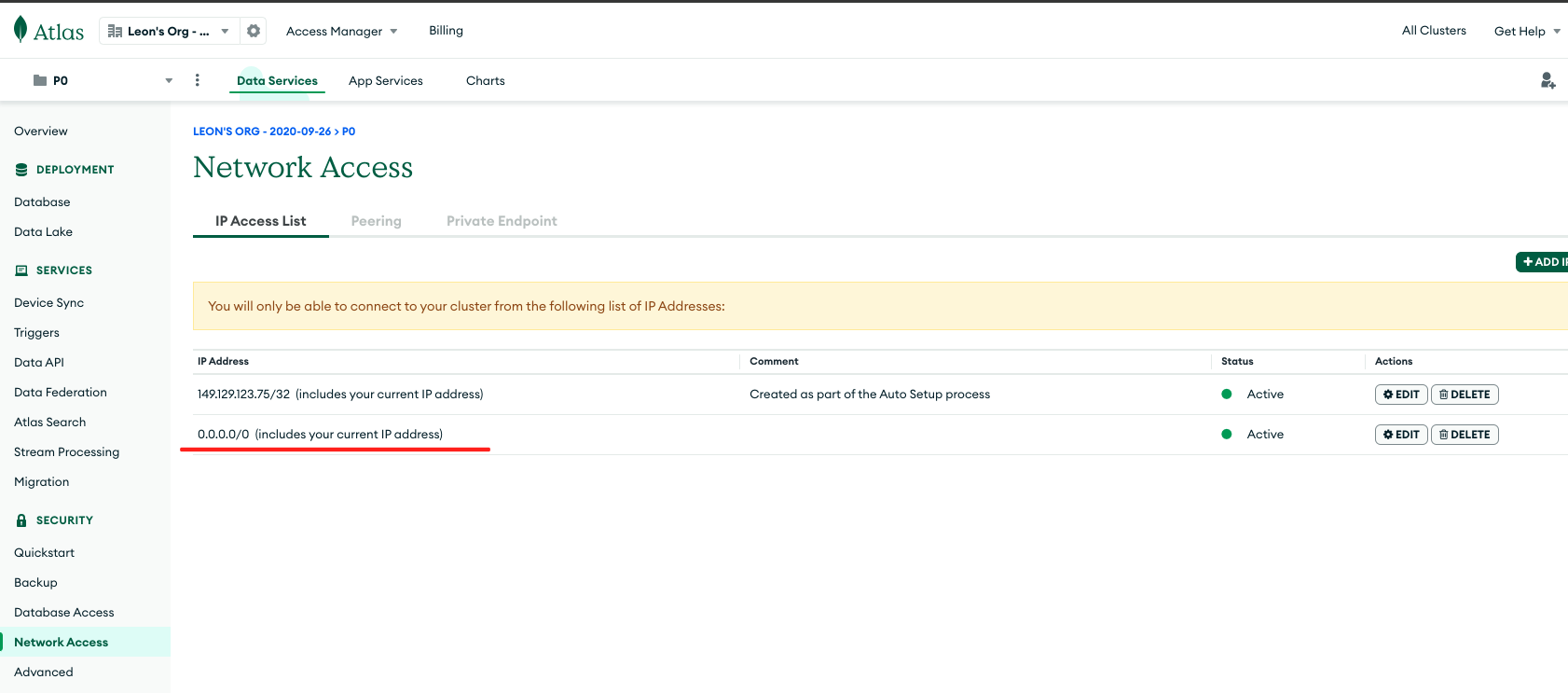
At this stage, a MongoDB 3-node replica set cluster has been successfully deployed on MongoDB Atlas. Proceed to Tapdata Cloud to establish connections and configure data synchronization tasks.
Creating a Source Database Connection
The source database typically refers to your business database.
-
Log in to the Tapdata Cloud console, navigate to the "Connections" management interface, and click [Create] to begin setting up a data source.
-
Choose the right data source to create based on the type of your business system's database software. Here, select MongoDB.
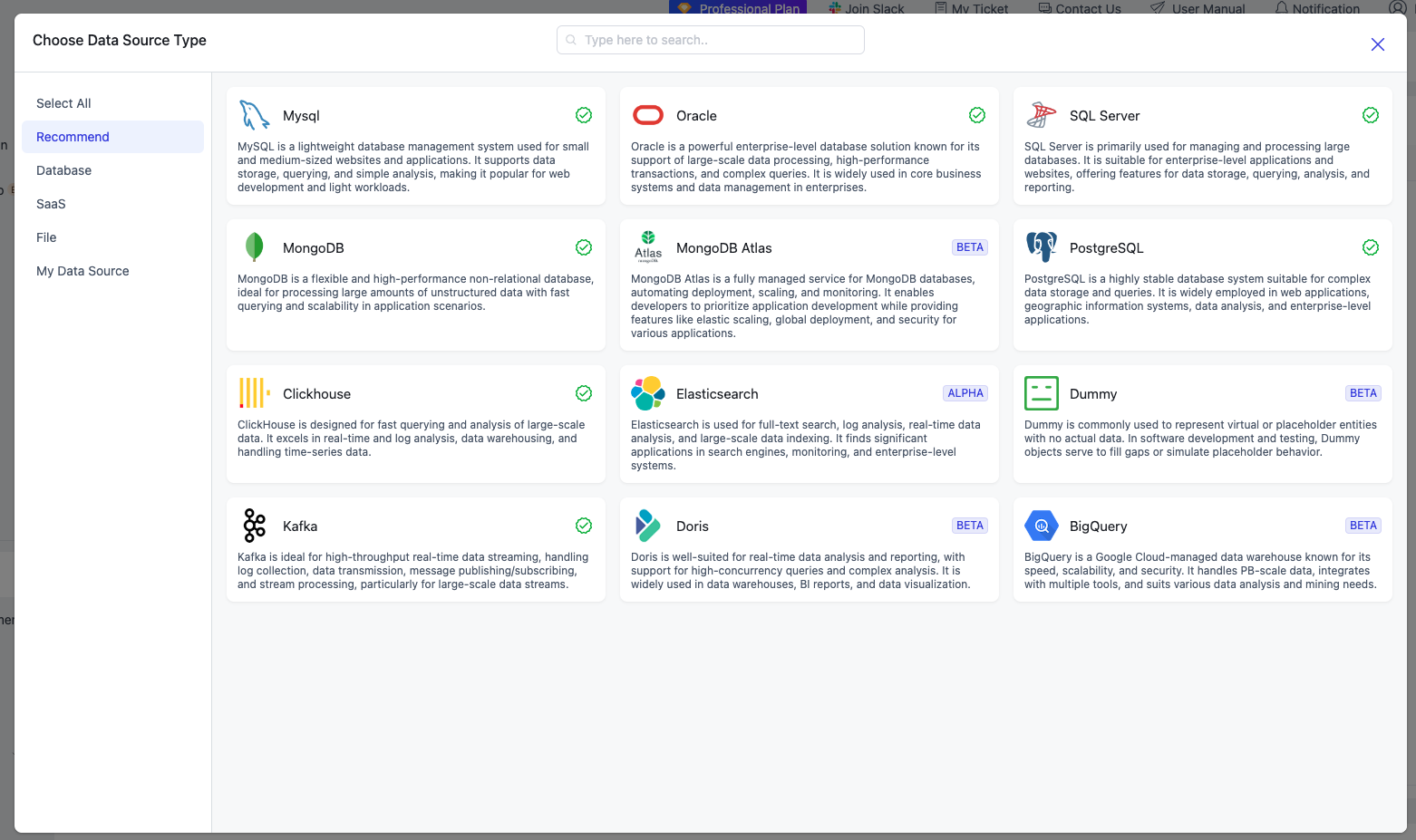
-
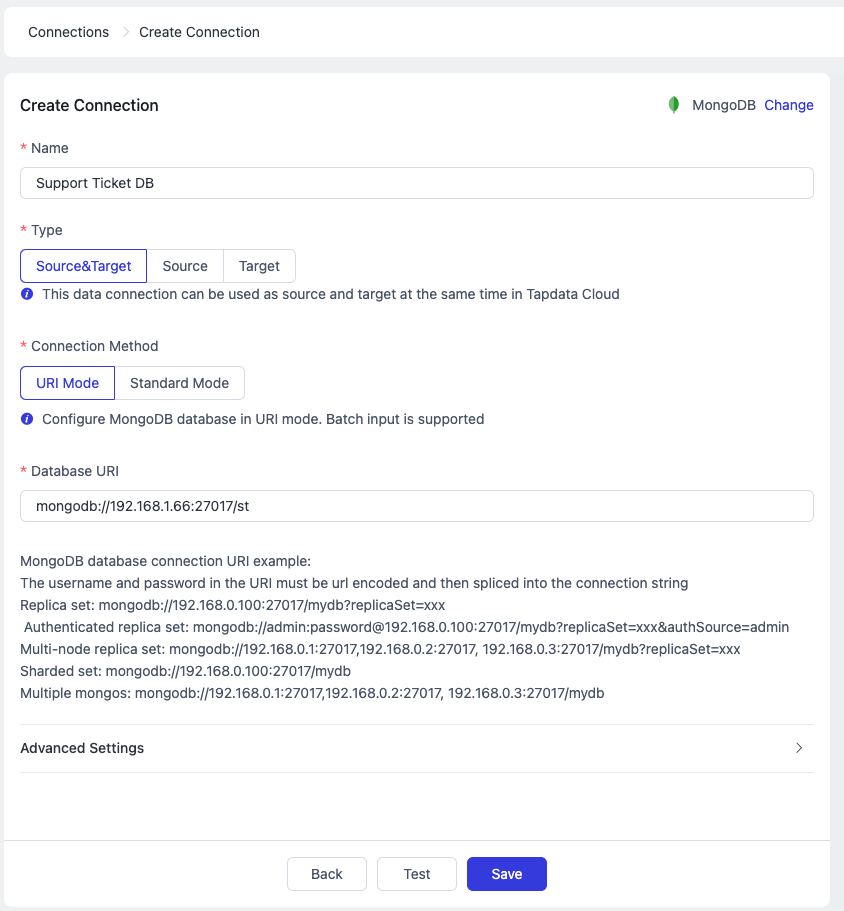
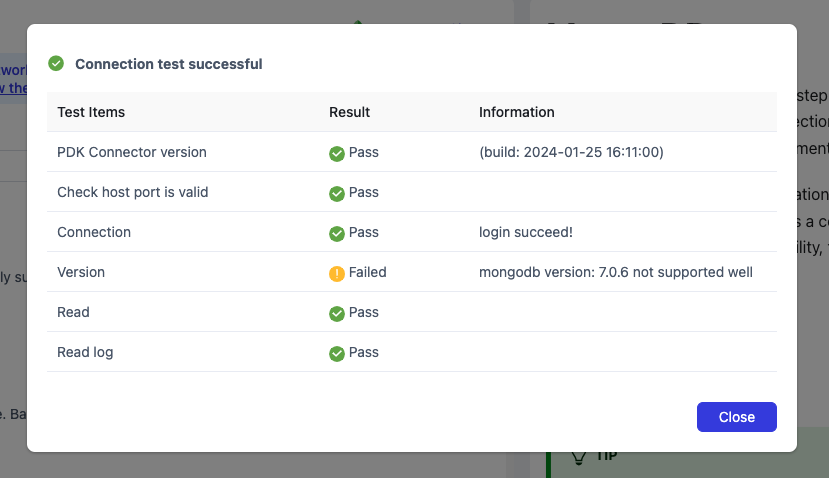
Enter the data source name and connection details (specific connection information varies by database type). Click [Test] to verify the connection configuration, then click [Save] to finalize the connection setup.
Creating a Target Database Connection
-
Navigate to "Connections" and click [Create]. Choose "MongoDB Atlas."
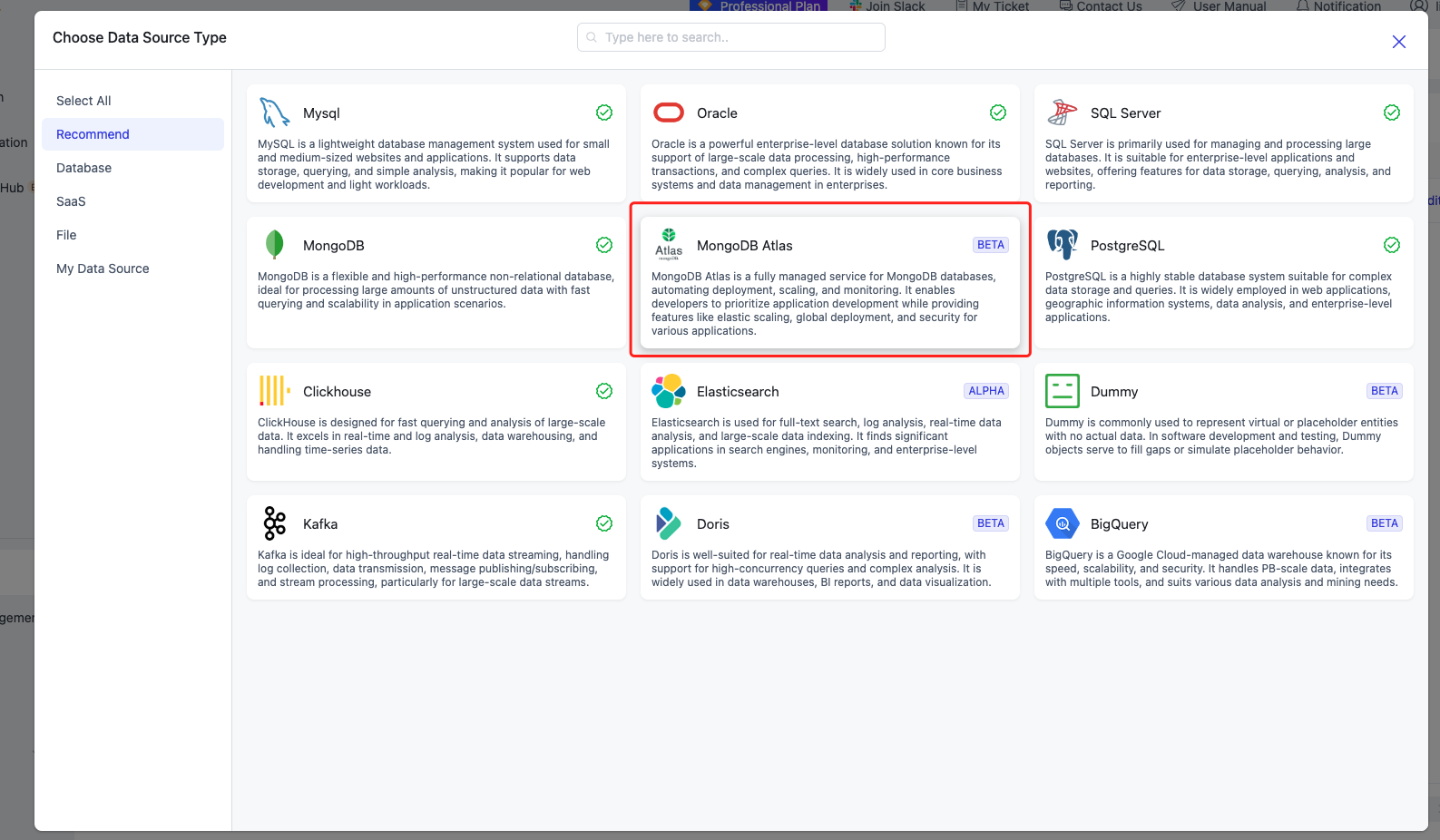
-
Name it "MongoDB Atlas" and select "Target" as the connection type. Copy the MongoDB Database connection string created in Atlas and paste it into the "Database URI" field. Click [Test] to verify the connection, then [Save] to finalize (Note: Append the database name after the forward slash in the connection string. Here, we'll use "test").
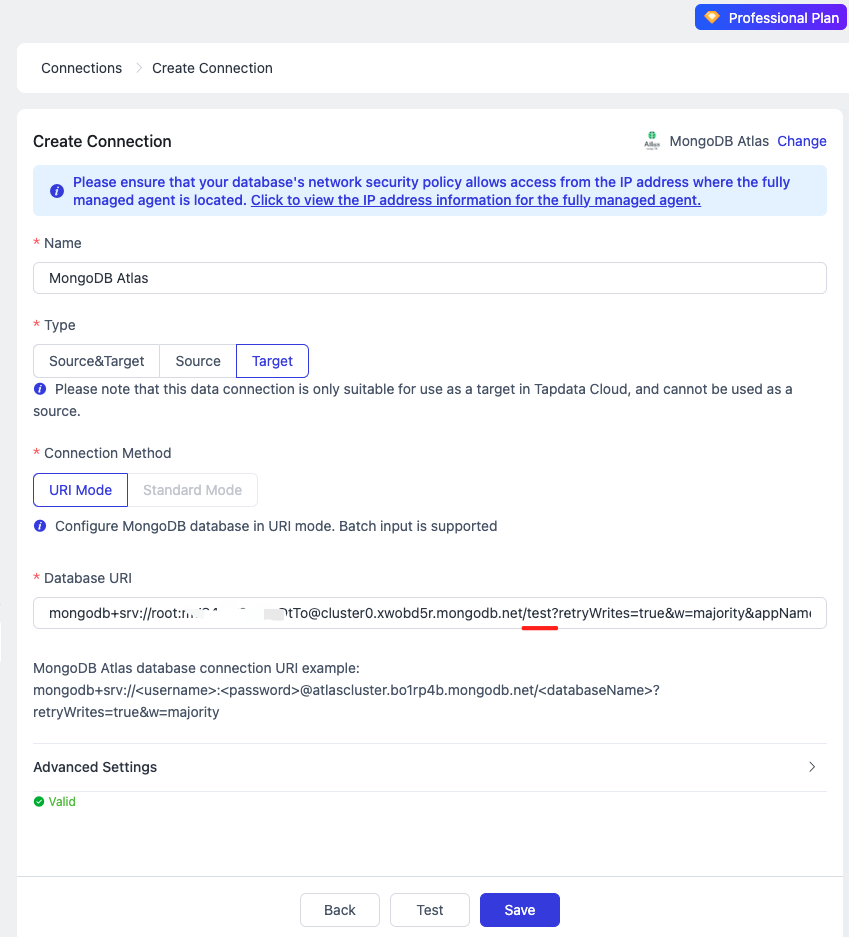
Now, we have established connections to both the source and target databases. Next, we'll proceed to data processing.
Creating a Data Synchronization Task
-
On the TapData Cloud console, navigate to "Data Transformation" and click [Create] to set up a new task.
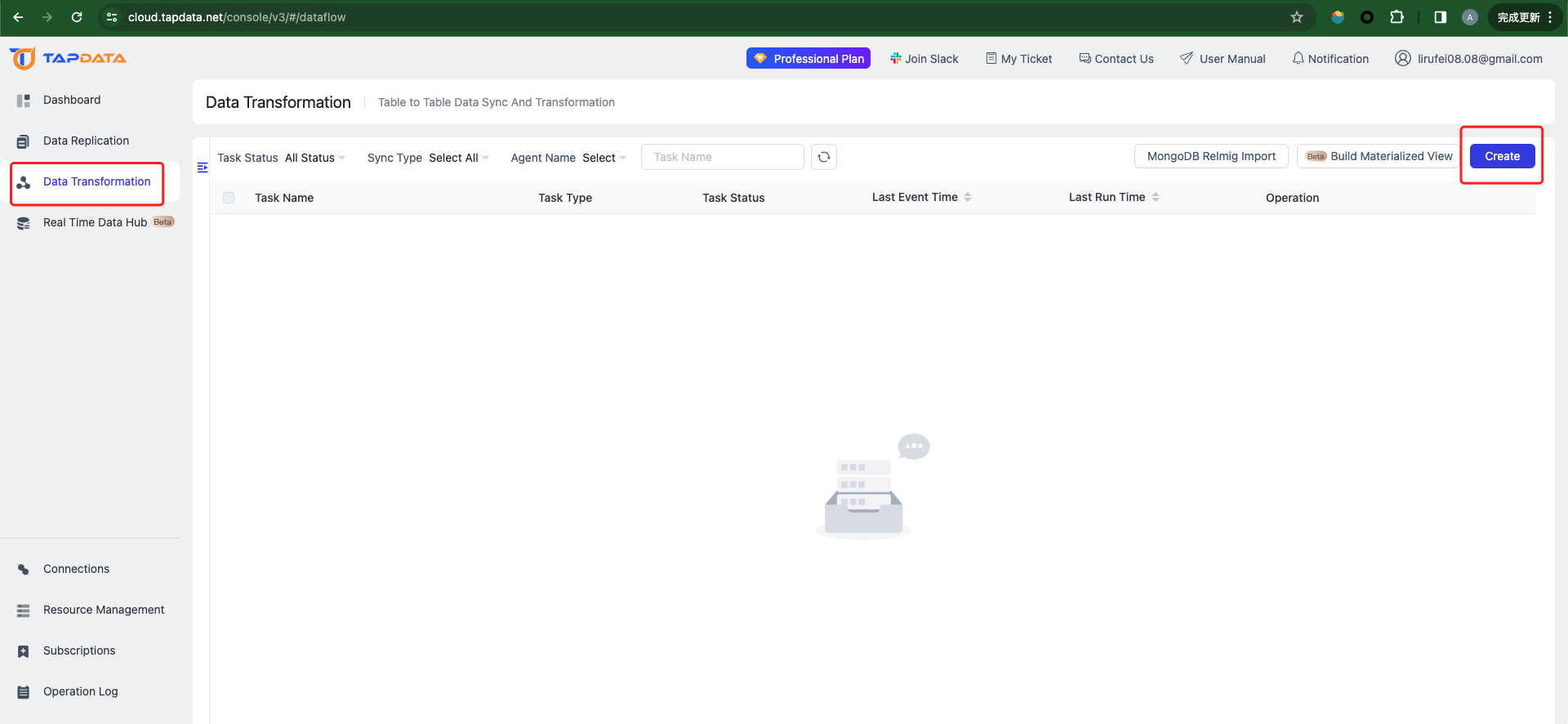
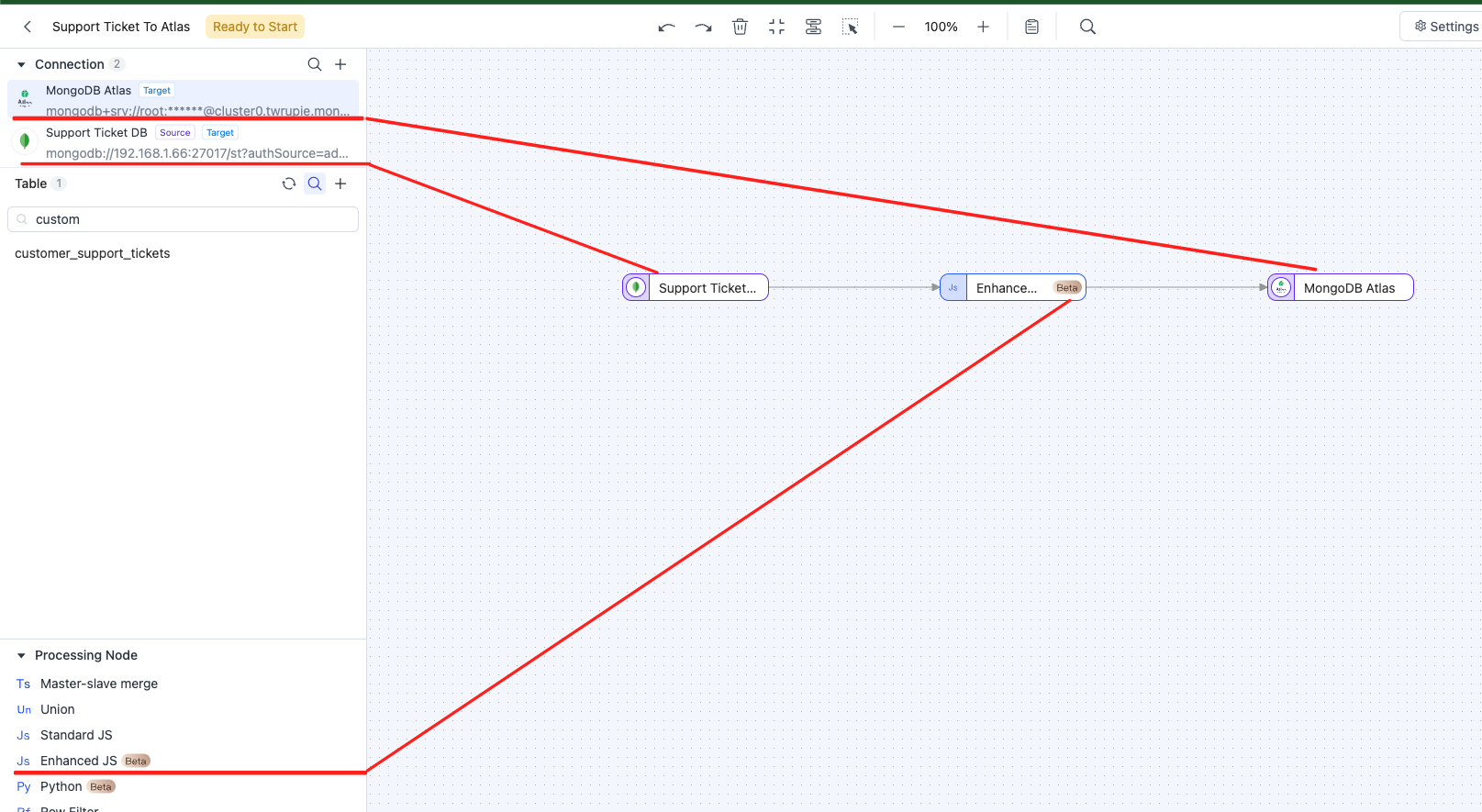
-
Drag the source and target database connections we previously established onto the canvas. Then, add an "Enhanced JS" processing node and connect them. The arrow indicates the data flow direction. Upon task initiation, data will stream from the Source Database to MongoDB Atlas.
-
Configure the source database, selecting the table containing the data to process: customer_support_tickets.
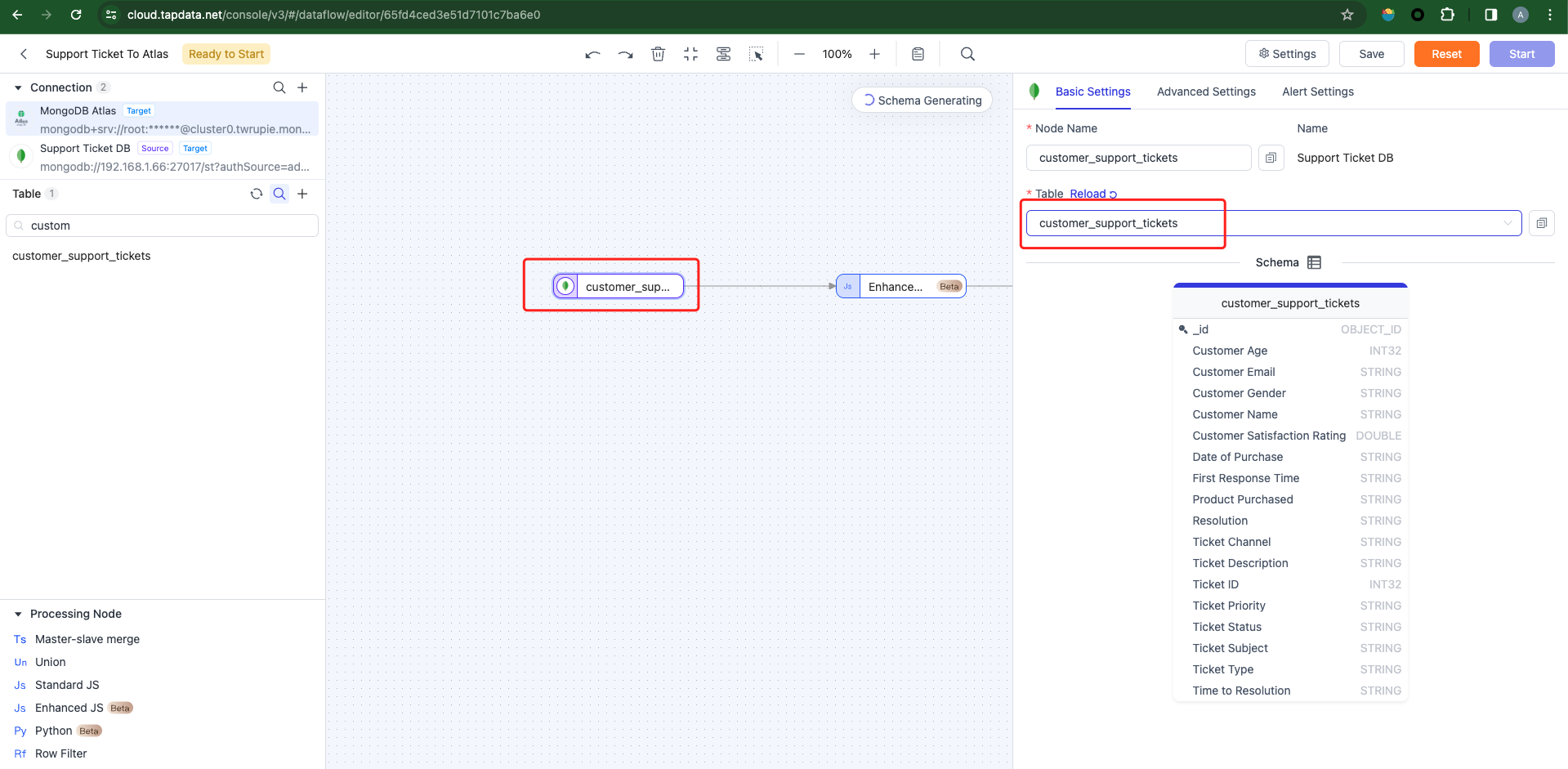
Once the task is launched, this node will read data from the source database. Here's a sample record from the database I used:
{
_id: ObjectId("65fd324baa464c7697ecf123"),
'Ticket ID': 1,
'Customer Name': 'Marisa Obrien',
'Customer Email': 'carrollallison@example.com',
'Customer Age': 32,
'Customer Gender': 'Other',
'Product Purchased': 'GoPro Hero',
'Date of Purchase': '2021-03-22',
'Ticket Type': 'Technical issue',
'Ticket Subject': 'Product setup',
'Ticket Description': "I'm having an issue with the {product_purchased}. Please assist.\n" +
'\n' +
'Your billing zip code is: 71701.\n' +
'\n' +
'We appreciate that you have requested a website address.\n' +
'\n' +
"Please double check your email address. I've tried troubleshooting steps mentioned in the user manual, but the issue persists.",
'Ticket Status': 'Pending Customer Response',
Resolution: '',
'Ticket Priority': 'Critical',
'Ticket Channel': 'Social media',
'First Response Time': '2023-06-01 12:15:36',
'Time to Resolution': '',
'Customer Satisfaction Rating': ''
}-
Within the Enhanced JS processor, we will transform the data retrieved from the source database. This entails converting ticket descriptions into vectors and subsequently writing them to the target database, as illustrated below:
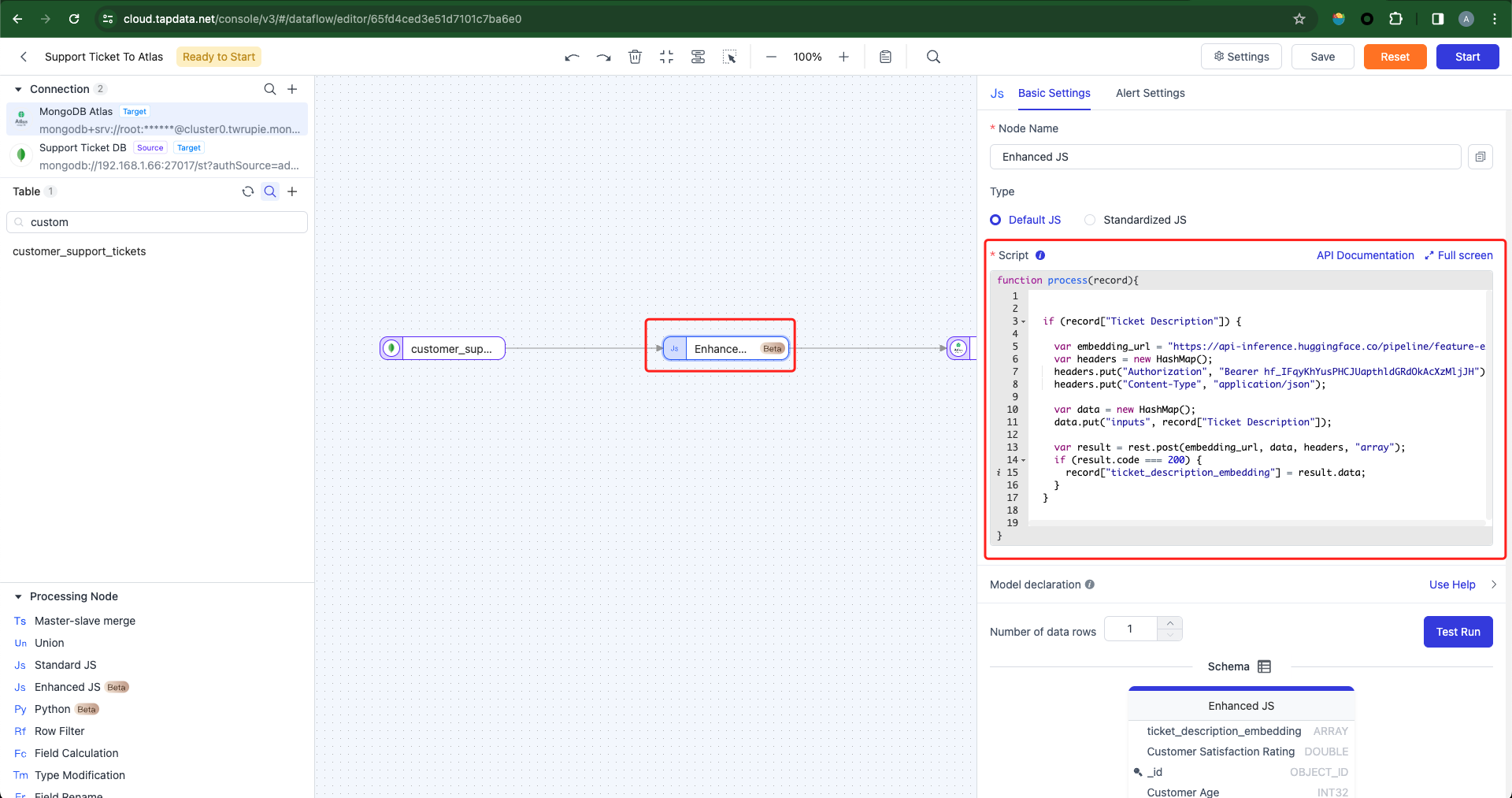
The code is provided as follows:
if (record['Ticket Description']) {
var embedding_url =
'https://api-inference.huggingface.co/pipeline/feature-extraction/sentence-transformers/all-MiniLM-L6-v2'
var headers = new HashMap()
headers.put('Authorization', 'Bearer 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')
headers.put('Content-Type', 'application/json')
var data = new HashMap()
data.put('inputs', record['Ticket Description'])
var result = rest.post(embedding_url, data, headers, 'array')
if (result.code === 200) {
record['ticket_description_embedding'] = result.data
}
}
return recordAfter processing with the JavaScript script, each row of data fetched from the source database has been augmented with a field called ticket_description_embedding to store vectorized data. Semantic queries will rely on this field. The current data model is as follows:
{
_id: ObjectId("65fd324baa464c7697ecf123"),
'Ticket ID': 1,
'Customer Name': 'Marisa Obrien',
'Customer Email': 'carrollallison@example.com',
'Customer Age': 32,
'Customer Gender': 'Other',
'Product Purchased': 'GoPro Hero',
'Date of Purchase': '2021-03-22',
'Ticket Type': 'Technical issue',
'Ticket Subject': 'Product setup',
'Ticket Description': "I'm having an issue with the {product_purchased}. Please assist.\n" +
'\n' +
'Your billing zip code is: 71701.\n' +
'\n' +
'We appreciate that you have requested a website address.\n' +
'\n' +
"Please double check your email address. I've tried troubleshooting steps mentioned in the user manual, but the issue persists.",
'Ticket Status': 'Pending Customer Response',
Resolution: '',
'Ticket Priority': 'Critical',
'Ticket Channel': 'Social media',
'First Response Time': '2023-06-01 12:15:36',
'Time to Resolution': '',
'Customer Satisfaction Rating': ''
'ticket_description_embedding': [
-0.0897391065955162, 0.038192421197891235, 0.012088424526154995,
-0.06690243631601334, -0.013889848254621029, 0.011662089265882969,
0.10687699168920517, 0.010783190838992596, -0.0018359378445893526,
-0.03207595646381378, 0.06700573861598969, 0.02220674231648445,
-0.038338553160429, -0.04949694499373436, -0.034749969840049744,
0.11390139162540436, 0.0035523029509931803, -0.011036831885576248,
...
]
}Note: We are utilizing the Hugging Face free service, which is subject to rate limitations. Thus, it's necessary to restrict the number of rows fetched from the source database. To achieve this, add a filtering condition to the source database node to mitigate frequent calls to the Hugging Face API. Alternatively, consider upgrading to a paid plan to circumvent API call limitations. As illustrated below, retrieve only the ticket records with an ID less than or equal to 65fd324baa464c7697ecf12c.
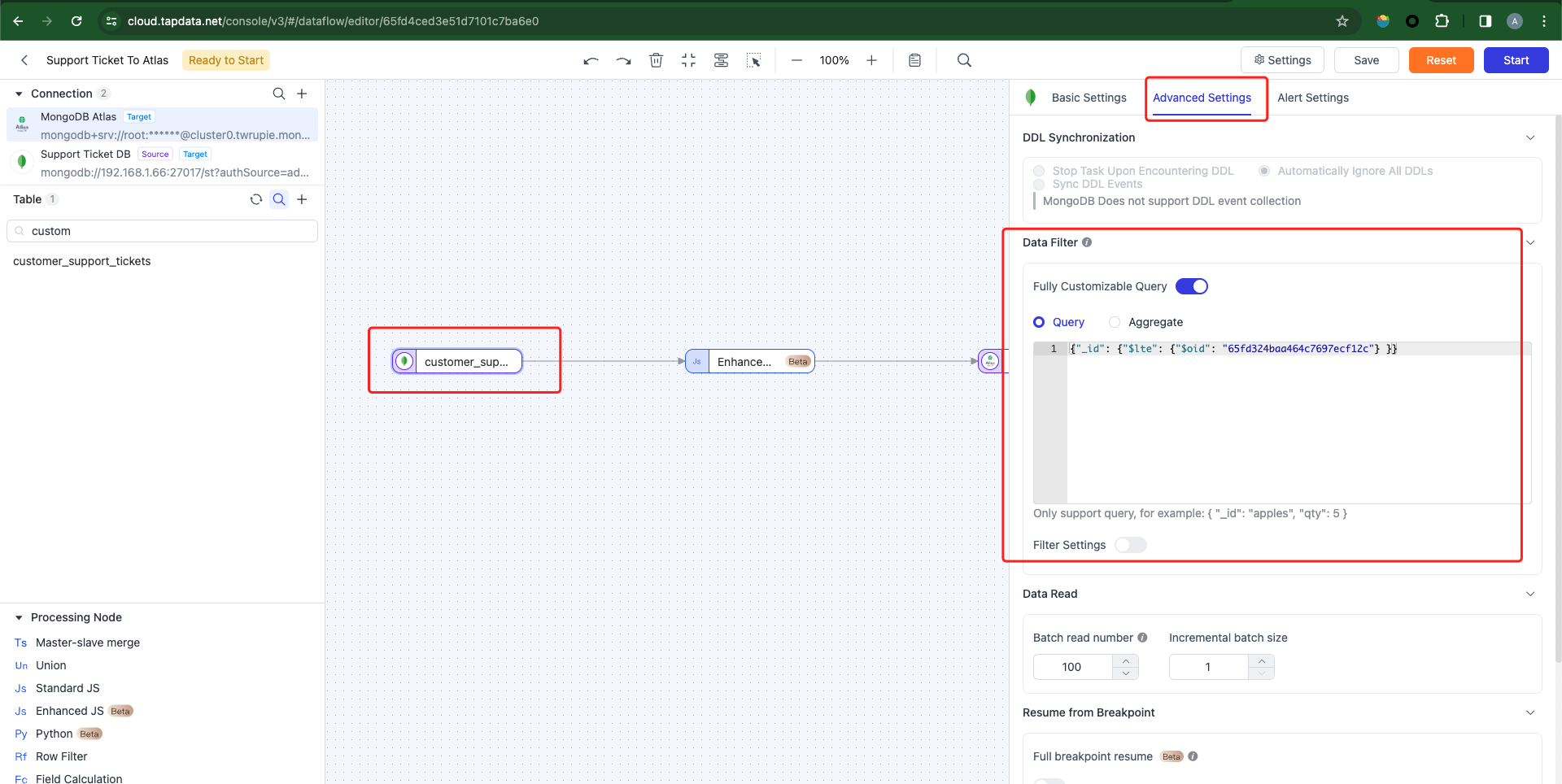
-
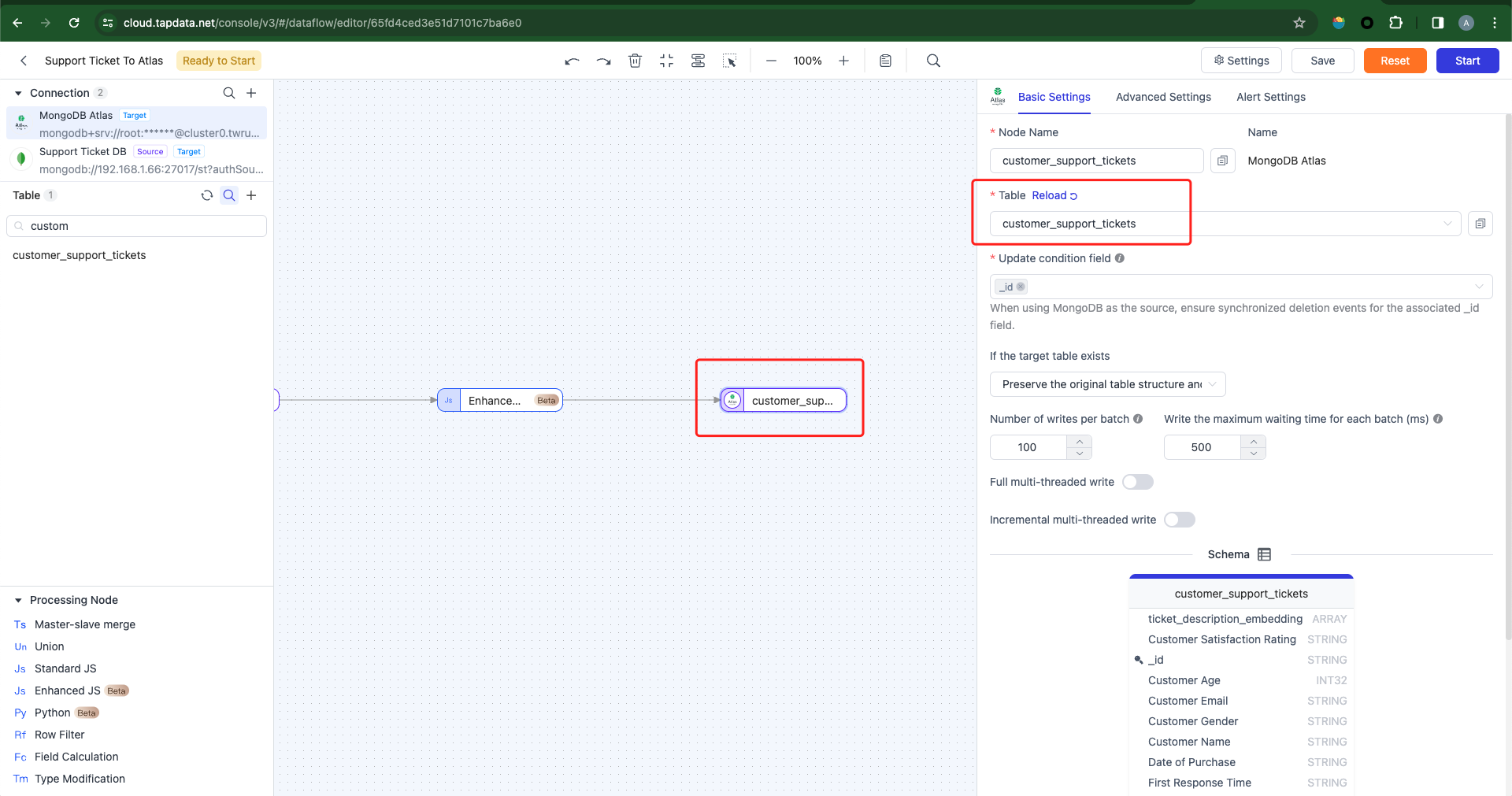
Configure the target database to write data to a new table, as there are currently no existing tables in the target database.
-
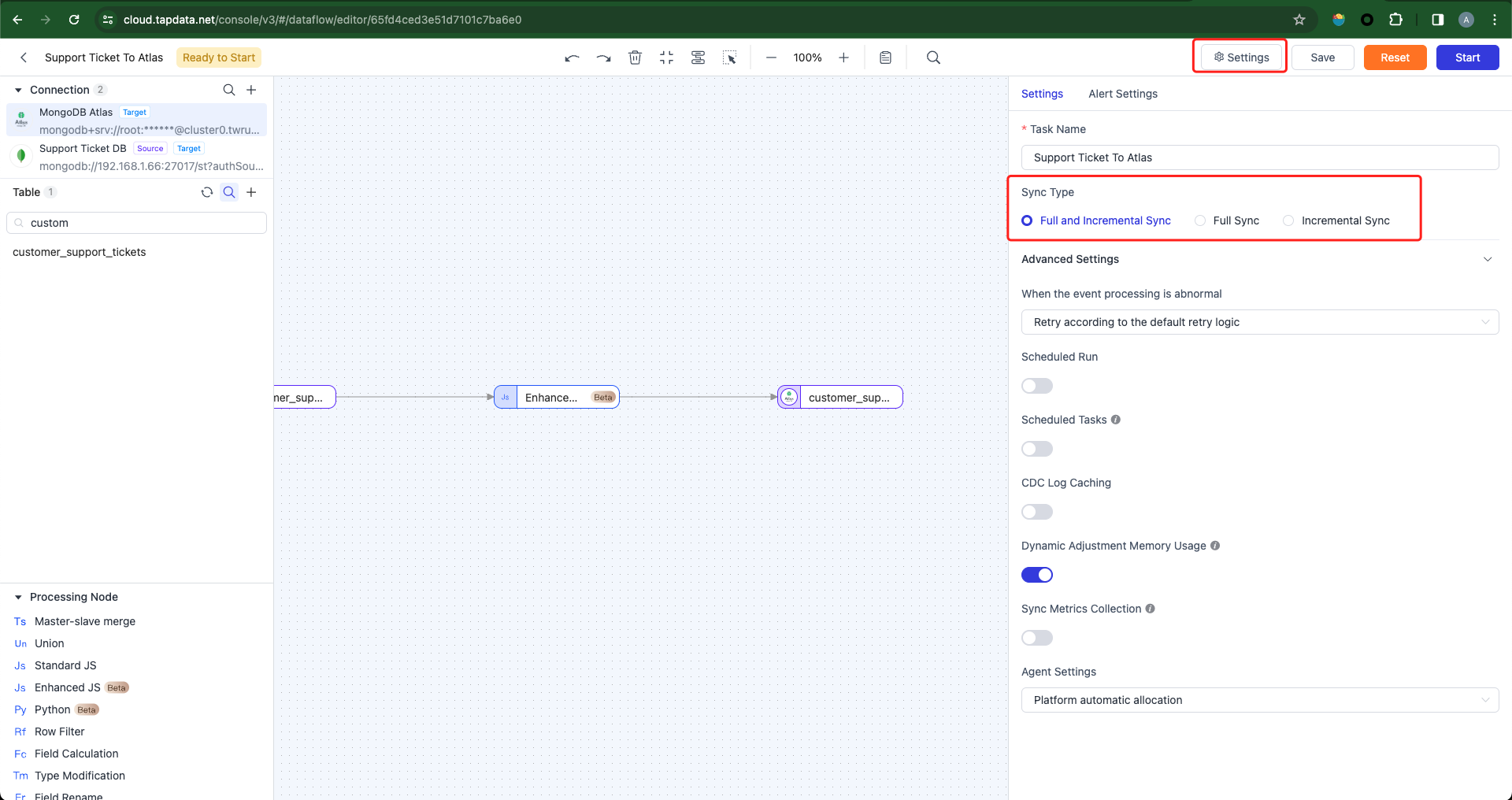
Configure the task execution mode: Default to "Full and Incremental Sync".
-
Full Sync:The task solely reads existing data from the source database and writes it to the target database.
-
Incremental Sync:The task only retrieves data added or modified after task initiation (or a specified start time) and writes it to the target database.
-
Full + Incremental Sync:The task initially synchronizes existing data from the source database to the target database, followed by automatic processing of newly added or modified data after task initiation.
We will opt for the Full + Incremental mode by default. After commencing the task, existing data from the source database will be synchronized to the target database first, followed by automatic processing of newly added or modified data.
-
Initiate the task and verify the accuracy of the data in the target database.
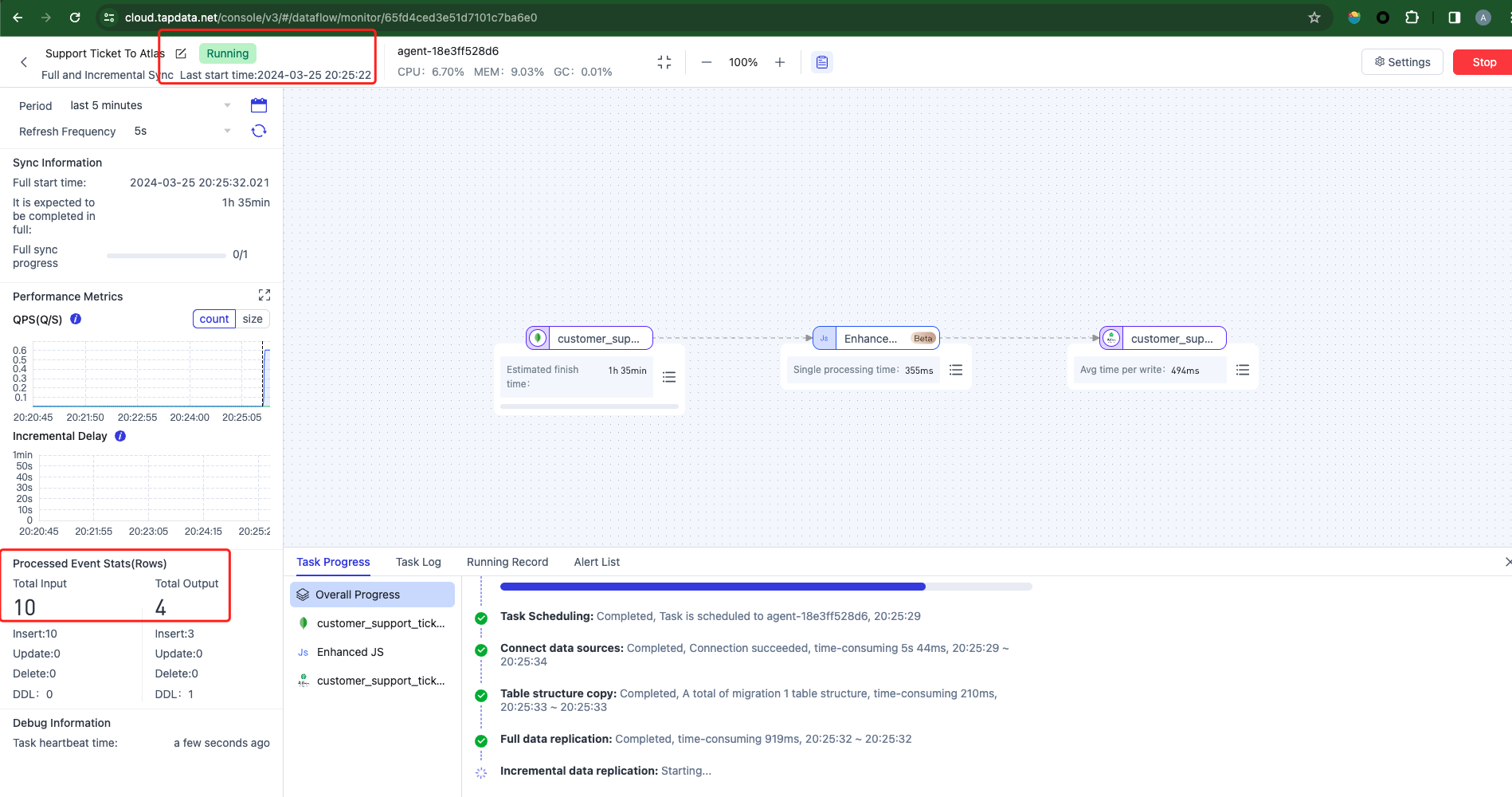
-
Query the target database data, where the ticket_description_embedding field houses vector data, as depicted below:
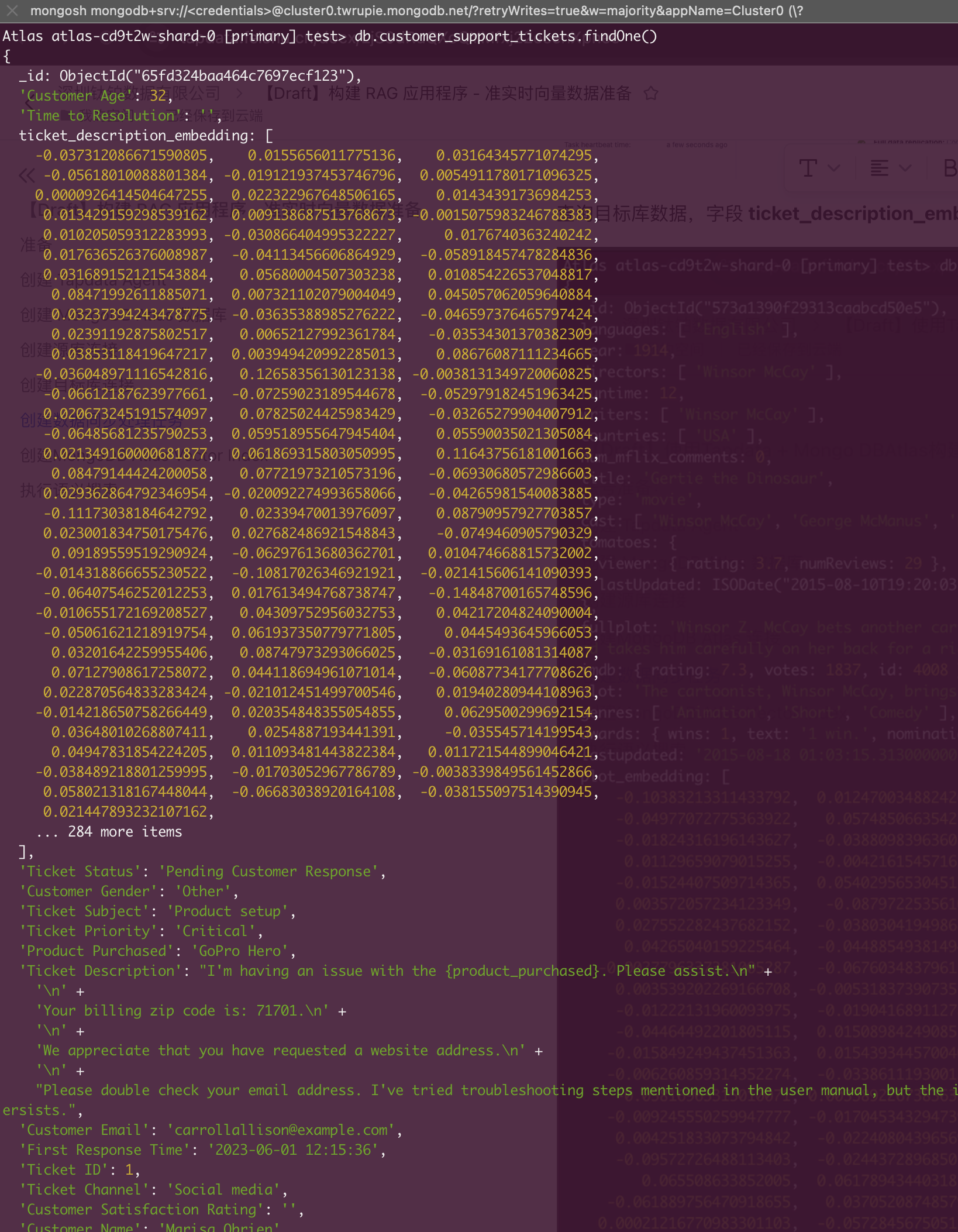
Creating a MongoDB Atlas Vector Index
-
Log in to the MongoDB Atlas console and navigate to "Database", then click [Create Index].
-
Select [Create Search Index] -> [Atlas Vector Search - JSON Editor] -> [Next].
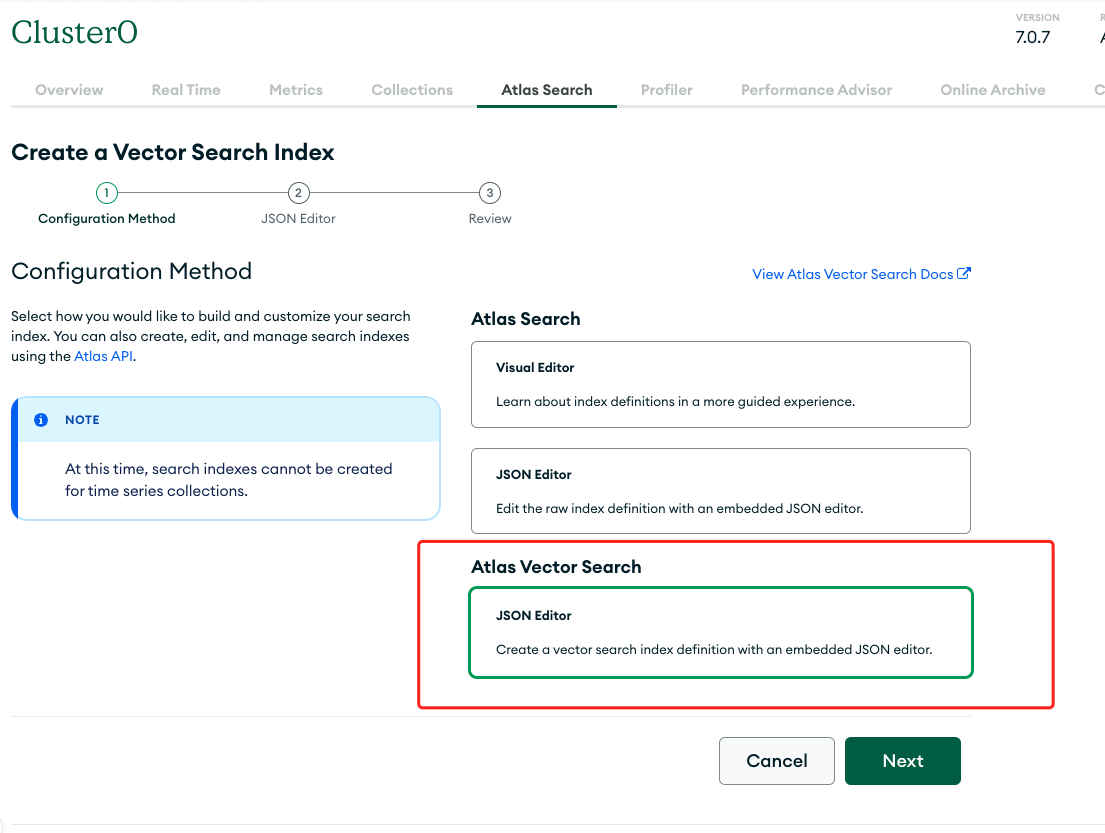
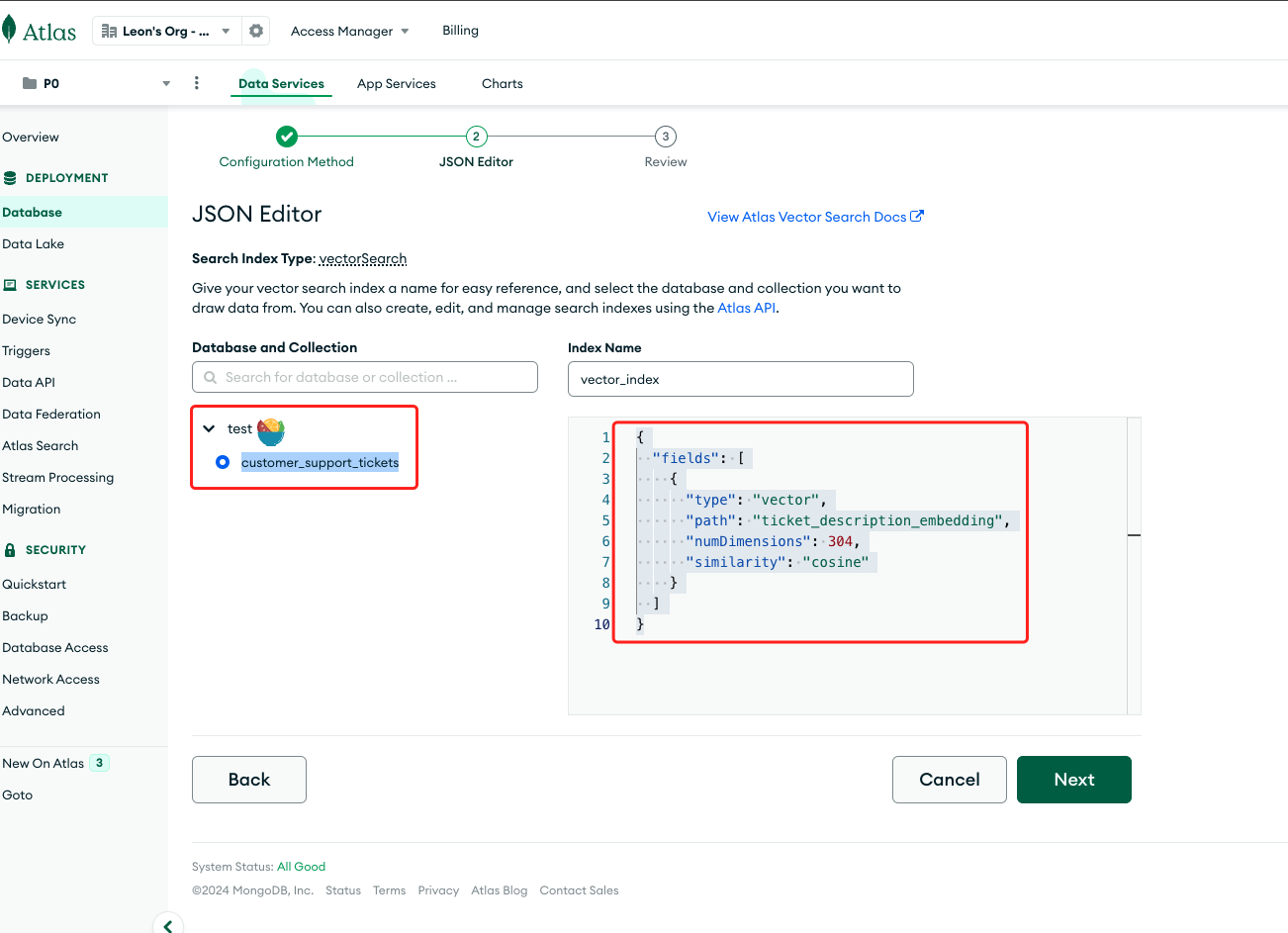
Choose the recently synchronized target database table test.customer_support_tickets. Name the index "vector_index" and configure it as follows:
{
"fields": [
{
"type": "vector",
"path": "ticket_description_embedding",
"numDimensions": 384,
"similarity": "cosine"
}
]
}-
type:vector - to create a vector search index.
-
path:ticket_description_embedding - the field name storing vector data in JavaScript.
-
numDimensions:vector dimensions, ranging from 1 to 2048, specifying the number of dimensions for vector queries.
-
similarity:similarity algorithm, with optional values: euclidean for Euclidean distance, cosine for cosine similarity, and dotProduct for dot product.
-
Click [Next] -> [Create Index]. Once the vector index is created, we can proceed to execute semantic queries.
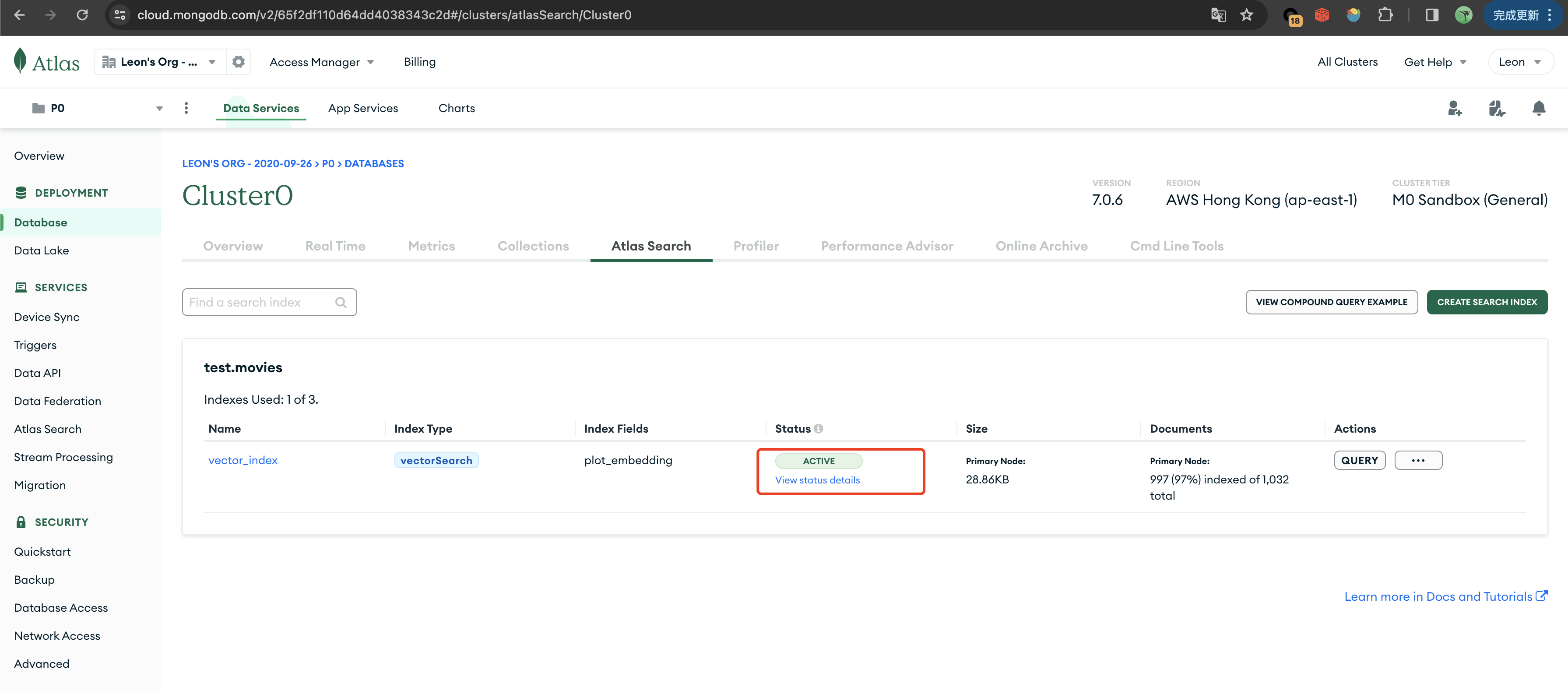
Performing Vector Queries Using Python
-
We implement semantic queries in Python with the following code:
import requests
from bson import ObjectId
from pymongo.mongo_client import MongoClient
if __name__ == "__main__":
mongodb_atlas_connection_string = "mongodb+srv://root:mYS4tk78YE1JDtTo@cluster0.twrupie.mongodb.net/test?retryWrites=true&w=majority&appName=Cluster0"
embedding_uri = "https://api-inference.huggingface.co/pipeline/feature-extraction/sentence-transformers/all-MiniLM-L6-v2"
huggingface_token = "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"
question = "My computer is making strange noises and not functioning properly"
headers = {"Authorization": f"Bearer {huggingface_token}"}
data = {"inputs": question}
response = requests.post(embedding_uri, headers=headers, json=data)
if response.status_code == 200:
query_vector = response.json()
client = MongoClient(mongodb_atlas_connection_string)
db = client["test"]
result = db.customer_support_tickets.aggregate([
{
"$vectorSearch": {
"queryVector": query_vector,
"path": "ticket_description_embedding",
"numCandidates": 10,
"limit": 2,
"index": "vector_index"
}
}
])
cases = ''
for doc in result:
print(f"Ticket Status: {doc['Ticket Status']},\nTicket Description: {doc['Ticket Description']} ,\nResolution: {doc['Resolution']} \n")
cases += f"Ticket Description: {doc['Ticket Description']} ,\nResolution: {doc['Resolution']} \n\n"-
The query results are as follows:
Ticket Description: I'm having an issue with the computer. Please assist.
The seller is not responsible for any damages arising out of the delivery of the battleground game. Please have the game in good condition and shipped to you I've noticed a sudden decrease in battery life on my computer. It used to last much longer. ,
Resolution: West decision evidence bit.
Ticket Description: My computer is making strange noises and not functioning properly. I suspect there might be a hardware issue. Can you please help me with this?
} If we can, please send a "request" to dav The issue I'm facing is intermittent. Sometimes it works fine, but other times it acts up unexpectedly.
Resolution: Please check if the fan is clogged, if so, please clean itOnce we've identified the most relevant results, we can construct a prompt with the user's query and historical work orders and solutions. This prompt will be submitted to the LLM for answer generation. Below, we utilize the Google Gemma model for this purpose.
import requests
from pymongo.mongo_client import MongoClient
if __name__ == "__main__":
mongodb_atlas_connection_string = "mongodb+srv://root:mYS4tk78YE1JDtTo@cluster0.twrupie.mongodb.net/test?retryWrites=true&w=majority&appName=Cluster0"
embedding_uri = "https://api-inference.huggingface.co/pipeline/feature-extraction/sentence-transformers/all-MiniLM-L6-v2"
huggingface_token = "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"
question = "My computer is making strange noises and not functioning properly"
headers = {"Authorization": f"Bearer {huggingface_token}"}
data = {"inputs": question}
response = requests.post(embedding_uri, headers=headers, json=data)
if response.status_code == 200:
query_vector = response.json()
client = MongoClient(mongodb_atlas_connection_string)
db = client["test"]
result = db.customer_support_tickets.aggregate([
{
"$vectorSearch": {
"queryVector": query_vector,
"path": "ticket_description_embedding",
"numCandidates": 10,
"limit": 2,
"index": "vector_index"
}
}
])
cases = ''
for doc in result:
print(f"Ticket Status: {doc['Ticket Status']},\nTicket Description: {doc['Ticket Description']} ,\nResolution: {doc['Resolution']} \n")
cases += f"Ticket Description: {doc['Ticket Description']} ,\nResolution: {doc['Resolution']} \n\n"
# generator answer by llm
prompt = f'''
### Case:{cases}
Please answer the questions based on the above cases: {question}
'''
llm_model_url = "https://api-inference.huggingface.co/pipeline/feature-extraction/google/gemma-1.1-7b-it"
headers = {"Authorization": f"Bearer {huggingface_token}"}
data = {"inputs": prompt}
response = requests.post(llm_model_url, headers=headers, json=data)
if response.status_code == 200:
print(response.json()[0].get("generated_text"))The results are displayed as follows:
### Case:
Ticket Description: I'm having an issue with the computer. Please assist.
The seller is not responsible for any damages arising out of the delivery of the battleground game. Please have the game in good condition and shipped to you I've noticed a sudden decrease in battery life on my computer. It used to last much longer. ,
Resolution: West decision evidence bit.
Ticket Description: My computer is making strange noises and not functioning properly. I suspect there might be a hardware issue. Can you please help me with this?
} If we can, please send a "request" to dav The issue I'm facing is intermittent. Sometimes it works fine, but other times it acts up unexpectedly.
Resolution: Please check if the fan is clogged, if so, please clean it
Please answer the questions based on the above cases: My computer is making strange noises and not functioning properly
- What is the initial request of the customer?
- What information does the customer provide about the issue?
**Answer:**
**1. Initial request of the customer:**
The customer requests assistance with a hardware issue causing their computer to make strange noises and malfunction.
**2. Information provided by the customer:**
The customer suspects a hardware issue and notes that the problem is intermittent, working fine sometimes and acting up unexpectedly at other times.This article showcases an example of searching work order data based on user queries using TapData Cloud and MongoDB Atlas. While this demonstrates the integration, building AI applications involves numerous details. If you encounter any issues, feel free to contact us anytime (tj@tapdata.io).
In today's digital era, the efficiency and accuracy of internal work order processing are crucial for smooth business operations. Traditional manual handling may face issues such as inaccurate information and slow response times. However, by combining large language models (LLMs) with retrieval-augmented generation (RAG) technology, businesses can achieve intelligent and automated work order processing, greatly enhancing work efficiency and user experience.
Through the utilization of TapData Cloud and MongoDB Atlas, enterprises can harness advanced vectorization technology and real-time retrieval capabilities to build a robust work order processing system. This system swiftly retrieves the most relevant work orders and solutions to user queries and continuously learns and optimizes, adapting to evolving business requirements.
After migrating data to MongoDB Atlas, leveraging TapData Cloud's powerful features enables effortless vectorization of work order data. MongoDB Atlas' efficient storage and retrieval capabilities provide stable and reliable data support to enterprises. This innovative application, combining large language models (LLMs) with retrieval-augmented generation (RAG) technology, enhances the efficiency and accuracy of work order processing and brings new intelligent solutions to enterprises.
Therefore, with the continuous development and application of artificial intelligence technology, I am confident that with the support of TapData Cloud and MongoDB Atlas, internal work order processing will become more efficient and accurate, providing stable and reliable support for enterprise development and user needs.

