
In today's fast-paced business environment, leveraging real-time data warehouses has become essential for effective analytics and business intelligence (BI). This capability allows companies to make informed decisions quickly, fueling growth and enhancing customer satisfaction.
A data warehouse is a system designed to store and manage data for BI purposes. Real-time data warehouses take this further by enabling the storage and near-instant analysis of data as it is generated.
In this article, we will delve into the concept of real-time data warehouses, their architecture, and how they differ from traditional data warehouses. We will also explore the primary use cases for real-time data warehouses and discuss the potential benefits for your business.
By the end of this article, you will have a comprehensive understanding of real-time data warehouses, their benefits, and best practices to maximize their effectiveness.
Let’s dive in.
What Is a Data Warehouse?
Imagine a data warehouse as a vast attic where you store all your valuable data. However, unlike a typical attic that merely holds items, a data warehouse is specifically designed to help you understand and analyze your data.
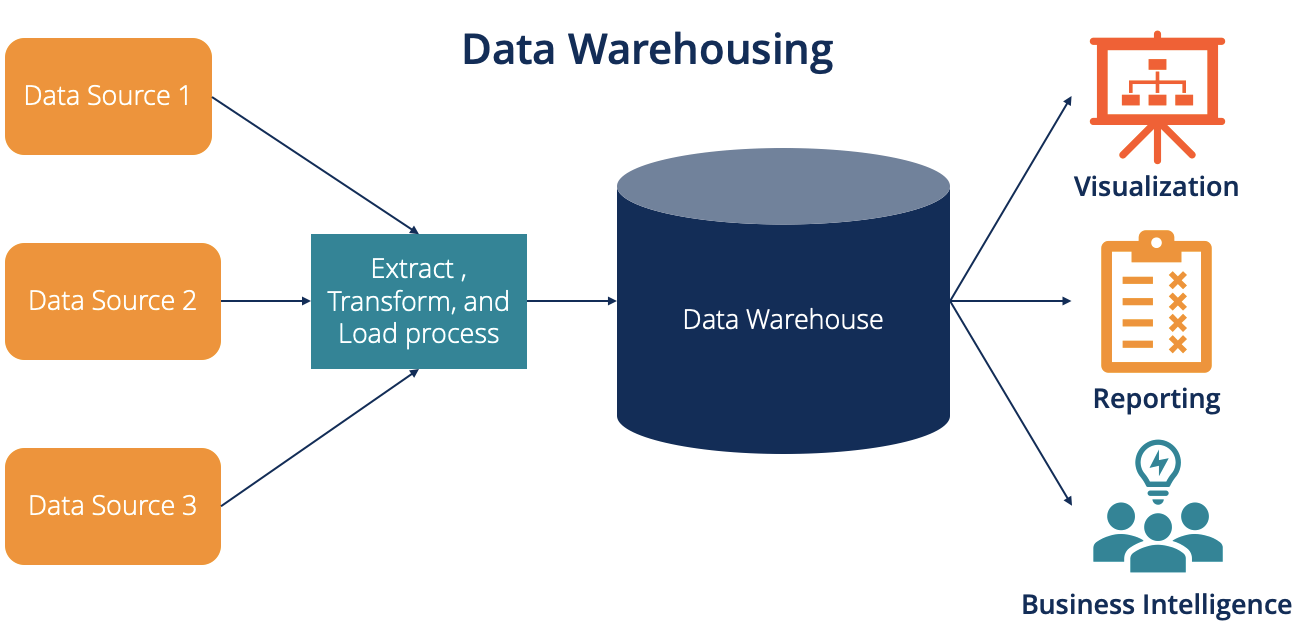
In technical terms, a data warehouse is an information system that aggregates and organizes data from multiple sources to provide meaningful business insights. It serves as the backbone of any large-scale analytics or BI project.
While traditional databases like MySQL and MongoDB are excellent for everyday operations, they often struggle with the demands of analyzing vast amounts of data. This is where a data warehouse proves its worth.
Purpose and Function
Data warehouses are built for analysis rather than transactions. They efficiently transform raw data into actionable information, making it readily accessible for users. Unlike operational databases, data warehouses store both current and historical data, enabling comprehensive decision-making processes.
For analytics, a data warehouse significantly improves response times and query performance. It is designed to handle complex queries quickly, saving time and enhancing the overall performance of data analytics.
Architecture
A typical data warehouse architecture is three-tiered:
-
Bottom Tier (Data Storage): This layer stores the cleaned and transformed data, ready for analysis.
-
Middle Tier (OLAP Server): The Online Analytical Processing (OLAP) server in this layer provides an abstract view of the database to end-users, allowing for efficient data analysis.
-
Top Tier (Client Layer): This layer consists of front-end tools like query tools, reporting tools, and analysis tools that provide access to the data.
This architecture ensures that data is efficiently stored, processed, and accessed, making it ideal for large-scale data analysis.
Characteristics
Data warehouses are subject-oriented, focusing on specific areas of interest. They bring consistency to various data types from different sources, ensuring that the data remains stable and unchanging. Additionally, they are time-variant, enabling the analysis of data changes over time.
Benefits
An efficient data warehouse offers:
-
Fast Query Times: Optimized for quick data retrieval and analysis.
-
Large Data Throughput: Capable of handling significant volumes of data seamlessly.
-
Data Transformation: Allows for the transformation of data to gain diverse insights.
In summary, a well-designed data warehouse not only stores data but also provides the tools and structure needed to extract valuable insights, enhancing decision-making and business intelligence efforts.
What Is a Real-Time Data Warehouse?
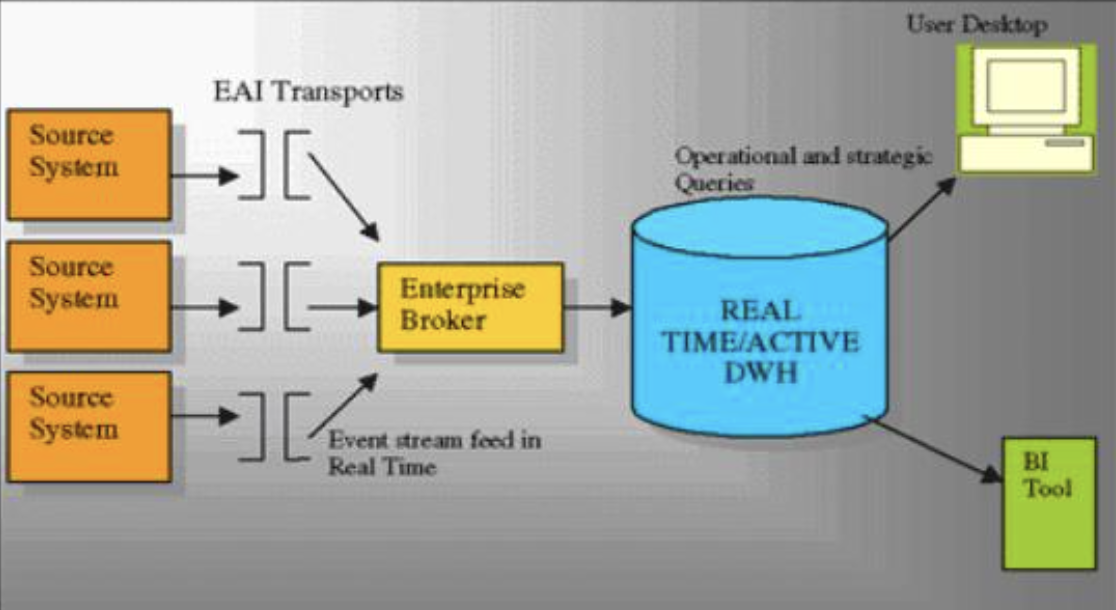
Real-time data warehouses (RTDWs) enable businesses to process data instantly, providing immediate insights into operations. This means you can access the latest information without waiting for batch processes or dealing with outdated data.
Benefits of Real-Time Data Warehousing
Real-time data warehousing allows you to stay ahead by making quick, informed decisions. The key to this swift processing is the implementation of real-time data pipelines. There are various open-source and managed solutions available for setting up these pipelines. For a scalable, no-code option, Estuary offers user-friendly tools that allow you to establish real-time data pipelines quickly.
How It Works
These pipelines efficiently transfer data from multiple sources to your data warehouse, centralizing all your information. An RTDW then processes this data immediately, enabling you to make decisions based on accurate and current information.
Differences from Traditional Data Warehouses
While RTDWs share similarities with traditional data warehouses, the scale and speed of data ingestion and processing set them apart. Data is ingested faster and transformed upon arrival, which enhances querying efficiency.
Additionally, queries in an RTDW run more quickly. If there are data errors that need correction, they must be addressed instantly before the data is stored.
Efficiency and Maintenance
In summary, real-time data warehousing offers efficiency and speed, keeping you competitive. While maintaining an RTDW can be challenging, it is manageable with the right tools and capabilities.
Real-time data warehousing is a powerful solution for businesses seeking to leverage immediate insights for better decision-making and operational efficiency.
Real-Time Data Warehouse vs. Traditional Data Warehouse
While traditional and real-time data warehouses might seem similar, they have significant differences that impact how businesses utilize data for decision-making.
Traditional data warehouses are designed to store and integrate all historical data from an organization. This consolidated data, gathered from multiple sources, is used to make business decisions. However, analysis based on this data typically reflects a past state, which might be days, weeks, or even months old when loaded.
Real-time data warehouses (RTDWs) build on the capabilities of traditional data warehouses by continuously refreshing data. This ensures that the data being analyzed provides an accurate and up-to-date view of the organization’s current state. As a result, businesses can quickly respond to emerging information and make strategic and tactical decisions based on the freshest data available.
Key Differences
-
Data Ingestion Frequency:
-
Traditional Data Warehouses: Data is stored and updated periodically, such as daily, weekly, or monthly.
-
Real-Time Data Warehouses: Data is ingested and updated continuously, often within minutes, providing real-time insights.
-
-
Data Currency:
-
Traditional Data Warehouses: Data analysis reflects a historical perspective, which can be outdated by the time decisions are made.
-
Real-Time Data Warehouses: Data is continuously refreshed, ensuring that analysis reflects the current state of the business.
-
-
Decision-Making Utility:
-
Traditional Data Warehouses: Primarily used for long-term strategic decisions due to the lag in data updates.
-
Real-Time Data Warehouses: Suitable for both long-term and short-term decision-making, thanks to the immediate availability of current data.
-
-
Correlation with Business Outcomes:
-
Traditional Data Warehouses: Correlating data with business outcomes can be challenging due to the time lag in data availability.
-
Real-Time Data Warehouses: Easier to correlate data with business outcomes, as the data reflects real-time operations.
-
-
Operational Continuity:
-
Traditional Data Warehouses: Updates can be done with scheduled downtime, as continuous updates are not typically required.
-
Real-Time Data Warehouses: Require continuous updates without shutting down, ensuring the data warehouse is always available.
-
Conclusion
Understanding the differences between traditional and real-time data warehouses is crucial for businesses aiming to leverage their data effectively. Traditional data warehouses provide valuable historical insights, but real-time data warehouses offer the immediacy needed for agile decision-making in today's fast-paced business environment.
With these distinctions in mind, let's explore the architecture of a real-time data warehouse to understand how it supports continuous data processing and real-time analytics.
Real-Time Data Warehouse Architecture
The explosion of big data and the increasing demand for real-time data analysis have driven the development of real-time data warehouses. These advanced systems are designed to deliver immediate insights and analytics by continuously capturing, storing, and processing vast amounts of data in real time.
This section will focus on the key components of real-time data warehouse architecture and the challenges associated with it.
Key Components of Real-Time Data Warehouse Architecture
A real-time data warehouse architecture comprises several critical components that work together to ensure the seamless flow and processing of data. These components include:
-
Data Ingestion Layer:
-
Stream Processing Engines: Tools like Apache Kafka, Apache Flink, and Apache Spark Streaming play a crucial role in ingesting data streams from various sources such as IoT devices, social media platforms, transactional systems, and more. These engines ensure that data is captured in real-time and delivered to the subsequent layers with minimal latency.
-
Message Brokers: Message brokers like RabbitMQ and ActiveMQ facilitate the reliable transmission of data between producers and consumers, ensuring that the data is consistently delivered to the processing layer.
-
-
Data Processing Layer:
-
Stream Processing Frameworks: Real-time processing frameworks such as Apache Storm and Samza provide the necessary tools to process and analyze streaming data. These frameworks support complex event processing, filtering, aggregation, and transformation of data on the fly.
-
In-Memory Computing: Technologies like Apache Ignite and Redis enable in-memory data processing, significantly reducing latency and improving the speed of data retrieval and processing.
-
-
Data Storage Layer:
-
Real-Time Databases: Databases such as Apache Cassandra, Amazon DynamoDB, and Google Bigtable are designed to handle high-velocity data and provide real-time read and write capabilities. These databases ensure that processed data is immediately available for querying and analysis.
-
Data Lakes: Data lakes like Apache Hadoop and Amazon S3 provide scalable storage solutions for both raw and processed data, allowing organizations to store vast amounts of data while maintaining the flexibility to process it in real-time.
-
-
Data Analytics Layer:
-
Real-Time Analytics Engines: Tools like Apache Druid and ClickHouse are optimized for real-time analytics, enabling organizations to perform complex queries and generate insights with minimal latency.
-
BI and Visualization Tools: Business Intelligence tools such as Tableau, Power BI, and Looker integrate with real-time data warehouses to provide interactive dashboards and visualizations, empowering decision-makers with timely insights.
-
Benefits of Real-Time Data Warehouse Architecture
Implementing a real-time data warehouse architecture offers numerous benefits to organizations, including:
-
Immediate Insights: Real-time data processing enables organizations to gain immediate insights from their data, allowing for quicker decision-making and more agile responses to changing business conditions.
-
Enhanced Customer Experience: By leveraging real-time data, businesses can offer personalized experiences to their customers, improving customer satisfaction and loyalty.
-
Operational Efficiency: Real-time data processing helps organizations identify and address operational issues promptly, leading to improved efficiency and reduced downtime.
-
Competitive Advantage: Organizations that can process and act on data in real-time gain a competitive edge by being able to capitalize on opportunities and mitigate risks faster than their competitors.
Challenges and Considerations
While the benefits of real-time data warehouse architecture are significant, there are also several challenges and considerations to keep in mind:
-
Data Quality: Ensuring the accuracy and consistency of real-time data is crucial. Organizations must implement robust data quality management practices to avoid erroneous insights.
-
Scalability: Real-time data processing requires scalable infrastructure to handle varying data volumes and velocities. Cloud-based solutions and distributed architectures can help address scalability challenges.
-
Latency: Minimizing latency is essential for real-time data processing. Organizations need to optimize their data pipelines and choose technologies that support low-latency operations.
-
Security and Compliance: Real-time data often includes sensitive information. Ensuring data security and compliance with regulatory requirements is critical to protect against data breaches and legal issues.
Role of ETL Tools
ETL (Extract, Transform, Load) tools are essential in real-time data warehouse architecture as they facilitate the continuous and efficient flow of data across various layers. Modern ETL tools are designed to handle real-time data integration needs, ensuring that data is consistently extracted, transformed, and loaded into the data warehouse with minimal delay.
-
Traditional ETL Tools: Tools like Informatica PowerCenter and Talend, while initially designed for batch processing, have evolved to support real-time data integration, providing robust data transformation and integration capabilities.
-
Real-Time ETL Tools: Tools like Apache NiFi, StreamSets, and TapData are specifically designed for real-time ETL processes. These tools can handle continuous data flows and provide features such as real-time data transformation, data cleansing, and integration with various data sources and destinations.
By selecting appropriate ETL tools, organizations can ensure seamless data integration and synchronization across the data ingestion, processing, storage, and analytics layers, ultimately enabling a more efficient and responsive real-time data warehouse architecture.
Conclusion
The real-time data warehouse architecture represents a significant advancement in data management, enabling organizations to process and analyze data as it is generated. By leveraging the key components of real-time data ingestion, processing, storage, and analytics, and integrating robust ETL tools, businesses can gain immediate insights, enhance customer experiences, and achieve operational efficiency. However, addressing the challenges of data quality, scalability, latency, and security is essential to fully realize the benefits of a real-time data warehouse.
By embracing real-time data warehouse architecture and selecting appropriate ETL tools, organizations can stay ahead of the competition and drive innovation in their respective industries.
7 Strategies for Real-Time Data Warehouse Success
In this part, we will delve into the key strategies that can lead to success in implementing a real-time data warehouse, including real-time data integration and change data capture, ensuring efficient operations and improved accuracy in data processing.
Strategy 1: Understand Your Business Requirements
Identify Key Data Sources
Internal Data Sources
-
Business Analyst Candidate Insights: A good business analyst candidate understands how to go about building the ideal inquiry and then drawing the data from that inquiry that will lead to insights useful toward moving the business forward.
-
Business Analyst Insights: Benefits of having a business analyst involved during the implementation of requirements include ensuring that the requirements are clear and unambiguous, which can help avoid misunderstandings and errors during implementation.
External Data Sources
-
Understanding data collection, evaluation, and communication is crucial for businesses. Being commercially astute, aware, and strategic are key attributes for effective decision-making.
-
Involving a business analyst can provide valuable feedback to the development team during testing and validation, improving the quality of the final product.
Strategy 2: Choose the Right Technology Stack

Evaluate Real-Time Data Processing Tools
Stream Processing Frameworks
-
Apache Kafka: Handles vast amounts of data streams with minimal latency and can ingest data from multiple sources. It integrates with popular stream processing frameworks like Apache Flink, Apache Storm, and Apache Samza to provide real-time data processing and analysis.
-
Google Cloud Dataflow: Designed to handle the complexities of processing data in real time. Empowers data scientists and engineers to focus on extracting meaningful insights from their data, rather than dealing with the intricacies of data streaming architecture.
-
Equalum: Unlocks the power of real-time data streaming, empowering organizations to process and analyze data streams as they flow.
Real-Time ETL Tools
-
Confluent Cloud: Built on Apache Kafka's foundation, it has a fault-tolerant architecture where data is replicated across multiple clusters for redundancy and protection against failures. Seamlessly integrates with popular data storage systems such as Apache Cassandra simplifying the migration process.
-
Azure Stream Analytics: A fully managed event-processing engine that ingests, processes, and analyzes streaming data from different sources with remarkable speed and efficiency.
-
Amazon Kinesis: A robust and scalable technology enabling businesses to benefit from streaming data potential by seamlessly integrating with various data sources for real-time ingestion, processing, and analysis.
-
TapData: an open-source real-time data platform that excels in low-latency data movement. It addresses the long-standing data integration challenge with a novel approach: leveraging CDC-based, real-time data pipelines instead of batch-based ETL and supporting a centralized data hub architecture as well as point-to-point integration.
Consider Scalability and Performance
Horizontal Scaling
-
Implementing horizontal scaling allows adding more nodes to a cluster to handle increased workloads effectively. This approach ensures seamless scalability without compromising performance.
-
Apache Kafka can scale horizontally by distributing partitions across multiple brokers, enabling efficient handling of high-volume data streams.
Vertical Scaling
-
Vertical scaling involves increasing the resources of a single node in a system. While it provides immediate performance enhancements, it may have limitations in handling sudden spikes in workload demands.
-
Google Cloud Dataflow offers vertical scaling capabilities by dynamically adjusting resources based on workload requirements for optimal performance.
Strategy 3: Implement Robust Data Integration
Real-Time Data Ingestion
Data Streaming
-
Data Streaming plays a pivotal role in enabling organizations to capture and process data continuously as it is generated. This real-time approach allows for immediate insights and decision-making based on the most up-to-date information available.
Change Data Capture (CDC)
-
Change Data Capture (CDC) revolutionizes data integration by identifying and capturing only the changes made to data sources, rather than processing entire datasets repeatedly. By focusing on incremental updates, organizations can reduce processing time and enhance the efficiency of their data warehousing processes.
Data Transformation and Cleaning
Data Normalization
-
Data Normalization is a crucial step in ensuring that data is structured consistently across all sources. By standardizing data formats and eliminating redundancies, organizations can streamline their data processing workflows and improve overall data quality.
Data Quality Checks
-
Data Quality Checks are essential for verifying the accuracy, completeness, and consistency of incoming data. Implementing robust validation processes ensures that only high-quality data enters the real-time data warehouse, minimizing errors and enhancing decision-making capabilities.
Strategy 4: Ensure Data Security and Compliance

Data Encryption
In-Transit Encryption
Data encryption during transit ensures that information is securely transmitted between systems. By encrypting data in transit, organizations safeguard sensitive information from unauthorized access or interception. Implementing robust in-transit encryption protocols, such as SSL/TLS, establishes secure communication channels and prevents potential data breaches during transmission.
At-Rest Encryption
Securing data at rest is vital for protecting information stored within databases or file systems. At-rest encryption safeguards data when it is not actively being used, adding an extra layer of defense against unauthorized access or theft. Utilizing strong encryption algorithms like AES ensures that data remains confidential and intact even if physical storage devices are compromised.
Compliance with Regulations
GDPR
The General Data Protection Regulation (GDPR) aims to enhance data protection rights for individuals within the European Union (EU). Organizations handling personal data falling under GDPR's scope must adhere to stringent guidelines to ensure user privacy and security. Compliance with GDPR involves implementing measures to protect personal information, obtain user consent for data processing activities, and promptly report any data breaches to regulatory authorities.
HIPAA
The Health Insurance Portability and Accountability Act (HIPAA) sets forth regulations that govern the protection of health information in the healthcare sector. Covered entities, including healthcare providers, health plans, and healthcare clearinghouses, must comply with HIPAA standards to safeguard patient confidentiality and maintain the integrity of medical records. Adhering to HIPAA requirements involves implementing strict administrative, technical, and physical safeguards to prevent unauthorized access to protected health information (PHI).
By prioritizing data encryption both in transit and at rest and ensuring compliance with regulatory frameworks like GDPR and HIPAA, organizations can fortify their real-time data warehouse security measures while upholding user privacy rights and maintaining data integrity.
Strategy 5: Optimize Data Storage and Retrieval
Use of Data Partitioning
Horizontal Partitioning
-
Enhances query performance by distributing data across multiple servers based on a defined key range.
-
Facilitates efficient data retrieval for large datasets, improving overall system responsiveness.
-
Ideal for tables with high write operations, allowing for better scalability and enhanced data management.
Vertical Partitioning
-
Divides tables vertically based on columns, optimizing storage and retrieval efficiency.
-
Enables faster query processing by reducing the amount of data read from disk.
-
Particularly beneficial for tables with varying access patterns or distinct sets of columns.
Indexing Strategies
Clustered Indexes
-
Organizes table rows based on the index key, speeding up data retrieval for range queries.
-
Improves query performance by physically sorting data in the order of the clustered index.
-
Suitable for tables frequently queried using range-based searches or sorted results.
Non-Clustered Indexes
-
Creates a separate structure from the table to store index key values and row identifiers.
-
Enhances query speed by providing quick access to specific rows without scanning the entire table.
-
Effective for optimizing search queries on columns not included in clustered indexes.
Strategy 6: Monitor and Maintain Performance
Real-Time Monitoring Tools
Performance Dashboards
Monitoring performance through Performance Dashboards allows organizations to track key metrics and indicators in real time. These dashboards provide a visual representation of data insights, enabling quick identification of trends, anomalies, and potential issues. By utilizing intuitive graphs and charts, stakeholders can make informed decisions promptly based on the current state of operations.
Alerting Systems
Implementing Alerting Systems enhances proactive monitoring by notifying stakeholders of critical events or deviations from predefined thresholds. These systems enable timely responses to emerging issues, preventing potential disruptions or downtime. By setting up alerts for specific conditions or triggers, organizations can maintain operational efficiency and address concerns promptly.
Regular Maintenance and Tuning
Query Optimization
Query Optimization plays a vital role in enhancing database performance by fine-tuning queries for efficient data retrieval. Optimizing queries involves analyzing execution plans, indexing strategies, and query structures to minimize response times and resource consumption. By optimizing queries regularly, organizations can ensure optimal database performance and responsiveness to user requests.
Resource Management
Effective Resource Management involves allocating resources efficiently to support real-time data processing requirements. By monitoring resource utilization patterns and adjusting allocations as needed, organizations can prevent bottlenecks and ensure smooth operations. Proper resource management ensures that systems have the necessary computing power, memory, and storage capacity to handle workloads effectively.
Expert Testimony:
Splunk Experts in Data Monitoring emphasize that monitoring improves data quality by detecting and correcting issues before they become significant problems.
Strategy 7: Foster a Data-Driven Culture
Training and Education
Workshops and Seminars
-
Change Management Professionals emphasize the pivotal role of workshops and seminars in fostering a data-driven culture. These educational sessions serve as platforms for imparting essential knowledge and skills to employees, empowering them to leverage data effectively in their daily tasks. By participating in workshops and seminars, individuals can enhance their understanding of data analytics, visualization techniques, and decision-making processes.
Online Courses
Satya Nadella highlights the significance of online courses in cultivating a data-driven culture within organizations. Online courses offer flexible learning opportunities for employees to acquire specialized data-related skills and stay updated on industry trends. Through structured online modules, individuals can deepen their knowledge of data analysis tools, statistical methods, and best practices in data management. Embracing online courses enables teams to build a strong foundation in data literacy and drive informed decision-making across all levels.
Encourage Data-Driven Decision Making
Leadership Support
A lack of good data culture can hinder organizational progress, as witnessed during a Senior Executive Meeting where intuition overshadowed factual insights. Effective leadership support is crucial for instilling a culture that values data-driven decision-making. Leaders play a vital role in promoting transparency, accountability, and trust in data-driven initiatives. By championing the use of data analytics tools and fostering a collaborative environment, leaders empower teams to make informed decisions based on accurate information rather than subjective opinions.
Employee Engagement
In transforming into a data-driven organization, Change Management Professionals underscore the importance of employee engagement. Engaging employees throughout the transition process cultivates a sense of ownership and commitment to leveraging data effectively. Organizations must prioritize open communication channels, training programs tailored to diverse skill sets, and recognition of individual contributions to foster a culture where every team member feels empowered by data insights. By encouraging active participation and feedback from employees, organizations can nurture a dynamic environment that thrives on innovation fueled by actionable data-driven strategies.
Conclusion
-
Real-time data warehousing simplifies operations, providing quick access to valuable data and reducing system management time, resulting in significant cost savings and increased profitability.
-
Understanding customer preferences allows for a personalized touch, raising satisfaction levels and making companies the preferred choice among consumers.
-
Automation of ETL processes streamlines reporting, saving time for analysts and executives, enabling more frequent and accurate reporting, ultimately boosting operational efficiency.
-
Improved visibility into quality control data facilitates real-time issue identification and resolution, leading to a remarkable 25% decrease in defects and rework.
Empowering Business Success with Real Time Data Warehouse Solutions
Real-time data warehouse solutions have become indispensable tools for empowering business success in today's data-driven world. By maximizing business insights and operational efficiency, organizations can extract valuable information from real-time data streams to make informed decisions that drive growth and profitability. These solutions enable businesses to analyze trends, identify opportunities, and mitigate risks promptly, giving them a competitive edge in the market.
Furthermore, real-time data warehouses play a vital role in driving innovation and agility within organizations. By providing access to up-to-date information and analytics, businesses can adapt quickly to changing market dynamics and customer preferences. This agility allows companies to innovate their products and services, respond swiftly to emerging trends, and stay ahead of the competition.
Ultimately, leveraging real-time data warehouse solutions leads to achieving sustainable growth through data-driven decision-making processes. By basing strategic initiatives on real-time insights, businesses can optimize their operations, enhance customer experiences, and drive long-term success. The ability to harness the power of real-time data not only improves operational efficiency but also positions organizations for continued growth and prosperity in an increasingly competitive business landscape.

