Recently, Tapdata was selected as a partner by MongoDB and officially added to the MongoDB Ecosystem Catalog, accessible through its partner portal. This is a significant milestone for TapData, so we prepared this webinar to showcase our capability of working with MongoDB.
During the Tapdata Webinar: Continuous Data Sync from Oracle to MongoDB/Atlas earlier this month, Tapdata's founder TJ introduced a unique solution for continuous data synchronization from Oracle to MongoDB (Atlas).
With this solution, we can keep mission critical business data in synchronization between legacy application built on top of RDBMS and modern application running on modern database such as MongoDB. This is often very useful in situations where you want to keep the legacy application continuing to run for an extended period.
>>> Below is a summary of the key highlights from this Webinar. To watch the full webinar replay, please subscribe to Tapdata's YouTube channel.
Why Continuous Replication to MongoDB ?
Reflecting on his transition from the relational database world to MongoDB over a decade ago, TJ emphasized his attraction to MongoDB's flexible document model. He highlighted how this model streamlines database interaction and reduces the need for extensive coding, enabling developers to concentrate on coding and programming logic rather than database administration.
Why MongoDB Stands Out?
Before we delve into replicating data to MongoDB, let's briefly touch on why MongoDB stands out. MongoDB is undeniably one of the most successful modern databases today. While traditional databases like Oracle, Sybase, and Postgres SQL have been around since the 80s or 90s, MongoDB has emerged as a leading choice in the past two decades. With over 47,000 customers and a monthly influx of over 140,000 developers into its community, MongoDB boasts unparalleled popularity.
The most crucial aspect that retains developers within the MongoDB ecosystem is its flexible document model. In addition, MongoDB distinguished itself as one of the pioneering solutions with scalable, sharding architecture, enabling efficient handling of large volumes of data and traffic while maintaining high performance. These features played a significant role in its widespread adoption. Fast forward to today, MongoDB has evolved into a mature product database after more than 15 years since its debut, with a vast user base. Our focus today will be on data replication into MongoDB.
Leveraging MongoDB for Enhanced Query Performance & Flexibility: Exploring Multiple Use Cases
As for why we aim to replicate data to MongoDB and why continuous replication is essential, here are some key use cases:
1. Query Acceleration
One key use case is query acceleration, aimed at addressing performance issues encountered in traditional single-node architecture databases such as Oracle, PostgreSQL and SQL Server, etc.

Using a specific airline enterprise customer of MongoDB as an example, their adoption of MongoDB originated from their initiative to develop a new application. This application aimed to empower passengers with more flexible flight search capabilities, enabling them to search by low-cost calendar, multiple airports in the region, and flexible transfer options — going far beyond simple date or departure/arrival airport searches.
These requirements led to a significant increase in query throughput for database to support. At the time, they relied on Oracle as their primary database for the flight searching and booking. However, it became apparent that non-clustered version of Oracle could not adequately handle the surge in queries—up to 100 times more concurrent queries—placing strain on the database. Consequently, they began seeking solutions capable of efficiently managing queries on a modern database platform.
Despite their intention to maintain the existing Oracle-based application, they recognized the need for a strategy to synchronize flight, inventory, and ticket data to MongoDB(after a careful comparison of multiple options). This migration was essential to facilitate high performance queries within a modern database environment. Thus, the pivotal question arose: how could they efficiently transfer data from the existing database to the new one, as fast as possible?
2. Customer Data Platform
Another use case involves a local established healthcare company that we are currently assisting.
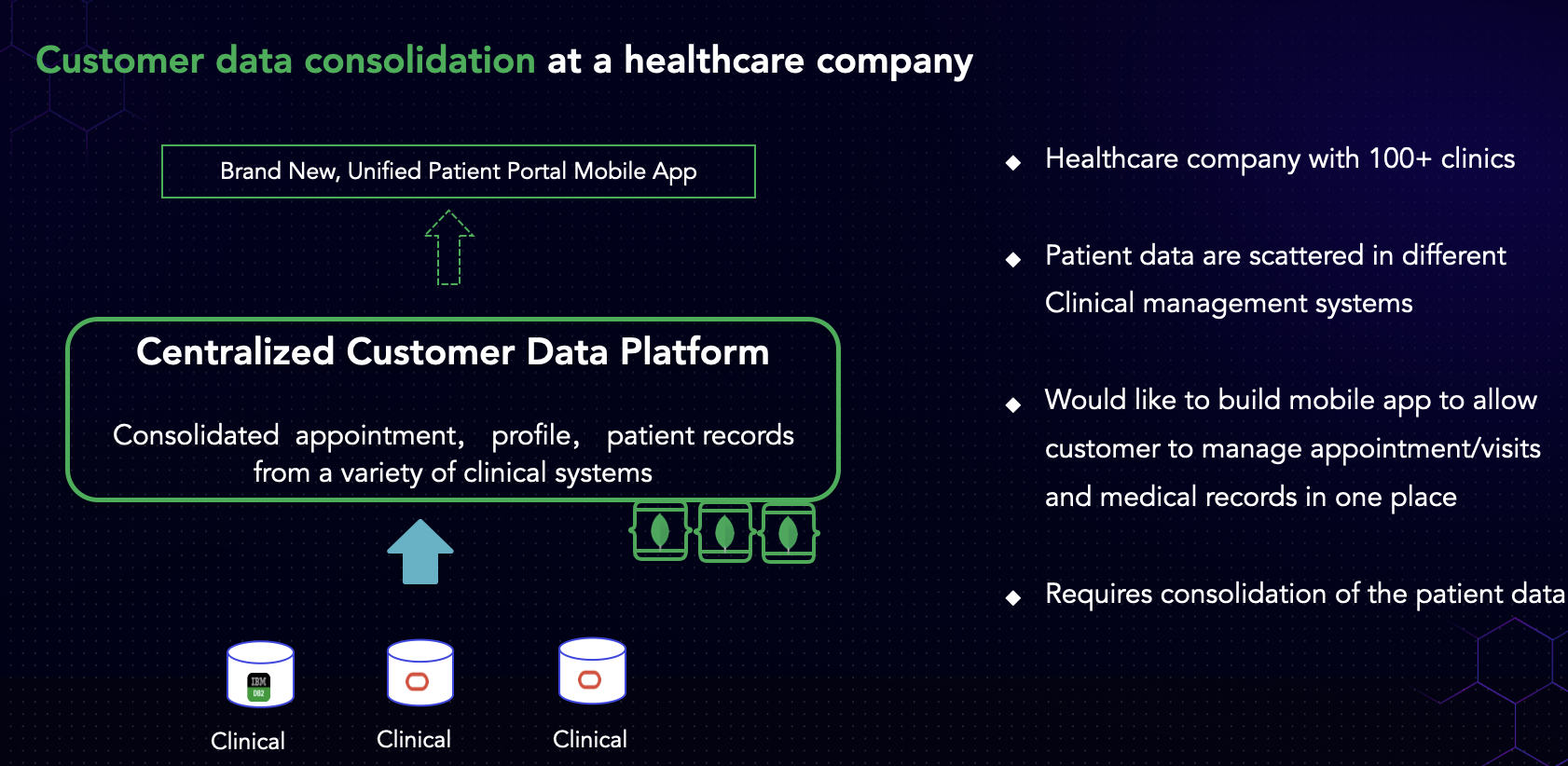
Their primary challenge stems from the accumulation of clinics over the years through merges & acquisitions. Currently, they manage nearly 100 clinics. However, due to the nature of these acquisitions, they have not necessarily integrated the operational systems or applications of these clinics, but only consolidated the business aspect. Consequently, while operating under a single brand, they still rely on various legacy application systems across different clinics.
With each clinic utilizing different systems—some developed in-house, some provided by vendors, and others off-the-shelf SaaS products—the company faces challenges in unifying their operations, particularly in appointment management, customer profile, and clinical records. They aim to enhance customer experience by enabling patients to book appointments across all clinics under their brand. However, the data is scattered and isolated within individual systems, hindering seamless communication and real-time updates. If you're relying on traditional batch methods, such as copying data every night or every other day, the data becomes less usable as appointments constantly change throughout the day in real-time.
To address this issue, the company seeks a solution to consolidate customer data into a single repository and make it readily available for a mobile app. Considering MongoDB Atlas as a potential solution, the key challenge lies in efficiently extracting data from disparate sources such as Oracle, MySQL, or DB2, and integrating it into MongoDB in real-time. This use case underscores the importance of migrating data to MongoDB to support new functionalities, particularly in the context of consolidation efforts.
With these two use cases, we can identify some commonalities:
-
Existing applications will continue to operate
-
Customer is building new app on modern database: MongoDB Atlas
-
Business data from legacy app need to be made available for new app, fresh
Firstly, both customers are not seeking to replace or rewrite their existing applications; instead, they intend to continue operating them while exploring new innovations. Secondly, they are leveraging modern database platforms like MongoDB Atlas for their new applications.
The primary challenge lies in ensuring seamless access to business data from legacy applications for these new applications. This necessitates ongoing synchronization of data between the two systems until a decision is made to decommission the current applications, which could be several years down the line or may not even be part of the plan. Therefore, a robust solution is required to facilitate continuous data movement and synchronization between these two environments.
What Are The Common Approaches?
What are the common approaches to addressing this problem? There are several methods, but two are widely adopted by organizations.
The first approach involves adding an API layer to the existing systems to expose the data to new applications. This method provides a straightforward means of accessing the data without directly modifying the legacy application.
The second approach is known as the dual-write method. With this approach, data is written not only to the current or legacy database but also to the new databases simultaneously. This ensures that both systems remain synchronized with the latest data.
Now, let's examine these two options:
① Adding API Layer to Existing System

As shown in the figure above, the first option involves setting up a new API service to expose the data from the current application running on Oracle to the new applications on the right side. To do this, we would develop a new API service, typically using Java or Python. Java is quite common and offers a quick setup process along with ease of design and implementation. Once the API component is in place, new applications can query it directly using HTTP requests or RESTful API methods. This approach is straightforward and often feasible to implement in-house, provided there are developers available to work on it.
However, there are some considerations to keep in mind. Introducing this new workload to the existing database, which may not have been provisioned or fine-tuned for this purpose, could potentially impact the performance of your application. Additionally, designing, developing, testing, and launching the new API service may require a significant amount of time. Furthermore, ongoing maintenance, monitoring, and potential performance issues with large queries impacting existing applications need to be addressed. These are important factors to consider when opting for this approach.
② Dual Writes to New Databases & Message Queue (Kafka)

Another widely-used approach, especially for multiple use cases, involves employing a messaging queue to route data or events between systems. Kafka is often chosen as it is a widely popular and reliable messaging solution for modern architecture.
The process typically entails modifying legacy applications to not only write data to the current database (e.g., Oracle) but also publish data changes (e.g., inserts, updates) using the Kafka API, sending them to a Kafka message topic. This enables the replication or distribution of changes to multiple downstream applications.
While this solution offers benefits in terms of data distribution and scalability, it also introduces complexities and overhead in managing the integration process. Implementing this approach requires significant time to modify existing applications and often entails ongoing maintenance. Integrating it into mission-critical workflows can be challenging due to potential risks and added complexity to the critical path. Additionally, additional coding work is involved, not only in modifying the original applications but also in writing consumer code to pull events from the Kafka message queue and possibly writing logic to insert data into MongoDB, as in our case. Along the way, various challenges such as network timeouts or errors may arise, requiring extensive error handling code. The consumer code also typically needs to handle the breakage and resumption, a very delicate matter indeed to manage.
Overall, while this solution offers benefits, it also requires careful consideration of its complexities and potential challenges during implementation.
Approach Review

Now, when we consider these solutions together, they are actually quite common and widely used by many companies and enterprises today. However, as mentioned earlier, they do come with some drawbacks as discussed.
Are there any other alternatives worth considering?
Our Solution: TapData Live Data Platform
YouTube Link: https://youtu.be/cDYYjSKcqKU
Quick demo of TapData Cloud
During the demo, you'll have the opportunity to see how quickly you can get started with TapData by signing up. We'll showcase two use cases:
-
Simple replication from Oracle table to Mongo collection
-
Replicating and Merging multiple Oracle tables into one Mongo collection
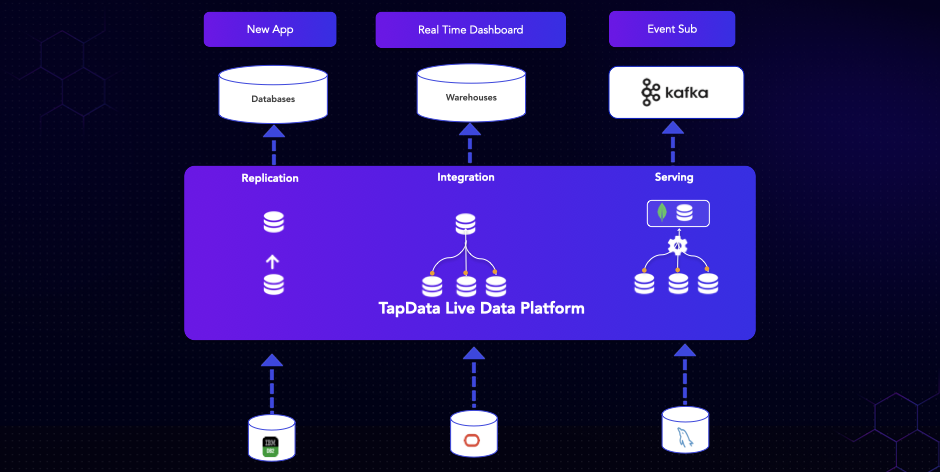
TapData is specifically designed to address the challenge of real-time data integration or movement within organizations. We've taken a unique approach to solving this age-old problem.

So, how do we do it? As illustrated in the diagram above, at the bottom represents your current application systems, typically running on popular relational databases like Oracle, MySQL, or SQL Server.
With TapData Live Data Platform, deploying and connecting is straightforward. Whether you choose our on-premises solution or opt for our cloud version, you simply connect or provision it. No extra coding is required; just provide the necessary credentials. We then leverage database log monitoring to instantly convert change events into streaming streams effortlessly.
These events come complete with payload and full record data for each row, allowing for optional filtering or transformation. Alternatively, you can proceed without any modifications.
Next, you have the flexibility to move this data to your desired destination. Whether it's sending it to Kafka for multiple consumers or storing it in modern databases like MongoDB or data warehouses for analytics, the possibilities are vast.
At the core of this capability is our Change Data Capture (CDC)-based data pipeline. In the next part, we'll delve into how it works.
Change Data Capture and Real Time Transformation

As shown in the diagram, on the left side, let's consider an application running on Oracle with a redo log, which is maintained by the Oracle database itself. Essentially, every database has a similar log file used to capture all changes in flat file mode for crash recovery and other purposes.
What we do is monitor this log, which contains all the increments: changes, inserts, updates, deletes. As soon as changes are applied to the log file, we capture and standardize them into processable events, and then optionally apply transformations or filters. Afterward, we move them to the destination, using different target plugins depending on the situation or target. In the legend scenario here, the target would be MongoDB.
Throughout this process, when an event occurs in Oracle, such as an order being placed or a status being changed, we instantly detect the change and move it to the chosen destination. Ideally, the latency in an optimal situation is subsecond. However, in reality, there may be a few seconds of near real-time delay. Thus, the entire real-time data pipeline allows you to have data in your destination within a couple of seconds of changes occurring in your source. Indeed, this is the pivotal mechanism at work.
A variety of Built-in CDC Connectors

To clarify, CDC capability is essential for capturing and processing real-time data changes from various databases. TapData simplifies this process by offering more than 60 pre-built CDC connectors, with which you can effortlessly capture data changes without the need for manual setup.
For most common databases like Oracle, SQL Server, PostgreSQL, Sybase, and DB2, we already have connectors available. You simply need to activate them, and you can instantly start capturing CDC events. Additionally, we support event capture from other databases, as well as from Kafka, MQs, or even SaaS APIs. Our aim is to offer a comprehensive solution that empowers you to access real-time data from any of your data sources seamlessly and efficiently.
Comprehensive MongoDB Data Model Support

When it comes to transferring data, especially concerning our discussion here about migrating data from a relational database to the modern Scalable Document Database, like MongoDB or MongoDB Atlas. MongoDB has a unique data model known as a denormalized document model, which differs significantly from the traditional relational table structure. This model allows for nested sub-documents and arrays, offering developers an intuitive way to represent complex real-world data.
Hence in our use case, the challenge lies in mapping data from, for example, Oracle to a modern database like MongoDB, bridging the gap between relational and document-oriented models. TapData addresses this challenge with a key capability specifically designed to handle such complex scenarios.
-
Relational to Document model, many to one real time merging
-
Embedded Array/Document
-
Automatically Insert / Update / Delete in sub documents
It seamlessly converts tables one-to-one or many-to-one. In MongoDB, best practices often involve designing a denormalized data model, consolidating multiple tables into a single collection. With TapData, you can replicate data from relational databases while also having the flexibility to combine, merge, or consolidate them according to your needs. And the final looking is a denormalized MongoDB collection that aligns with MongoDB's document-oriented approach.
Conclusion

Now, let's briefly review and compare the three solutions for making data available to new applications.
From the perspectives of development effort, impact on existing applications, and subsequent maintenance & enhancement, TapData demonstrates the following advantages:
- No Code & Low Code: Simplify the process with drag-and-drop functionality. User-defined functions (UDFs) with some low-code scripting are available for more complex tasks.
- Minimal Code Intrusion & Database Impact: TapData only requires connection to your database and compared to querying your database directly, TapData only looks at your log files, avoiding competition for database resources during reads and writes.
- Real-Time Monitoring & Alerts: TapData, being a mature data integration platform, equipped with real-time monitoring and alerts for seamless operations.
Explore Now
TapData is a CDC based real time data integration platform, available in Cloud, Enterprise, and soon Community edition. And it can actually handle much more than just moving data from relational databases to MongoDB.
>>> Schedule a Tapdata demo now to explore further.
>>> Start your real-time data journey with a free Tapdata trial today.
>>> Contact Us: team@tapdata.io
We highly encourage you to explore our cloud version, which is incredibly easy to deploy and use. With just a simple sign-up, you can start using it in no time once your environment is ready. And with our TapData Cloud premium option, currently deployed on GCP with plans for expansion to AWS and other Microsoft clouds in the future, you can enjoy two pipelines for free as long as your account remains active and the pipelines are in use. We also offer enterprise solutions, and in the near future, we'll be introducing a community edition as well.

Our Story
Make Your Data on Tap
Tap
"Whenever my friends and I visited restaurants or bars, we'd often inquire of the server: 'What's On Tap Today?' It was our way of seeking out the latest offerings in fresh, artisanal brews. There's something truly delightful about pulling that tap handle, watching the beer flow out, and taking that first sip – it's an experience brimming with freshness and yumminess, a simple pleasure I've cherished."
TapData
"When I worked as Principal Solutions Architect at MongoDB, I had the privilege of engaging with large scale customers, such as TSMC, China Eastern Airlines, etc. One common challenge they faced was the existence of disparate business systems, resulting in what we refer to as data silos. As these organizations sought to innovate and explore new business opportunities, they found themselves entangled in the complex and inefficient process of extracting and transforming data from various source databases, a process commonly known as ETL. It was during these encounters that a novel idea took root within me: what if we could bridge these isolated systems in a meaningful way, equipping each with its own 'tap'? Imagine, at your command, the ability to effortlessly access a continuous stream of data, much like turning on a faucet. This notion inspired the birth of tapdata – Make your data on tap. My earnest aspiration is that through our endeavors, we can furnish enterprises with a data platform that seamlessly connects these fragmented islands, empowering users to access their data with the same ease and freshness as enjoying a cold, freshly poured beer on a scorching summer day." ——TJ

